
เราเชื่อว่าหลายคนคงพบเจอปัญหานี้กับมาแล้วทั้งนั้นกับคำว่า “เดือนชนเดือน” ทำไมได้เงินเดือน เงินพิเศษมาพอถึงสิ้นเดือนก็เกือบจะหมดพอดี หรือเลวร้ายกว่านั้นคือใกล้จะหมดหลังจากได้เงินมาแปปเดียว เพราะต้องจ่ายหนี้ให้คนโน้นคนนี้บ้าง ส่งเงินให้ที่บ้านบ้าง
แถมการรับเงินหรือจ่ายค่าโน่นค่านี่ก็กระจัดกระจายไปหมด จ่ายเงินสดบ้าง จ่ายผ่าน Application ของธนาคารเอง แถมจะปรับแต่งให้ตรงตามใจเราก็ไม่ค่อยจะได้อีก

จะดีกว่ามั้ยถ้าเราสามารถ tracking พฤติกรรมการใช้เงินหรือสุขภาพการเงินของเราเองได้ตลอดเวลาว่า ทำไมเราถึงมีเงินเก็บน้อยหรือไม่มีเงินเหลือเลย นำไปสู่ปรับพฤติกรรมการใช้ชีวิตของตัวเองในวันข้างหน้า ทำให้มีเงินสำรองแบ่งไว้ลงทุนหรือวางแผนสร้างตัวสร้างอนาคตที่ดี

โดยเราจะใช้เครื่องมือที่ทรงพลังมากและฟรีด้วยอย่าง Google Sheets เครื่องมือสร้าง Spreadsheets ได้ฟรีแค่เพียงสมัคร Google Account (Gmail) ก็ใช้งานได้ทันที
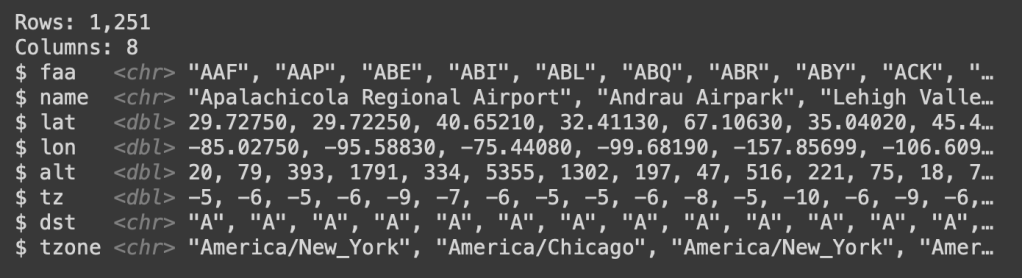
ข้อดีอย่างหนึ่งเลยของ Google Sheets คือ workspace ที่ใช้งานจะเป็นรูปแบบ tabular ที่มีทั้ง Rows และ Columns ที่เหมือนกับ Relational Databases ใน SQL เลย
- สร้างชีทใหม่ภายใน 5 วินาที
- ตั้งชื่อชีทใหม่
- แบ่งชีทให้ชัดเจน
- ตั้งชื่อ header ให้บัญชีรายรับรายจ่าย
- ตั้งค่า column วันที่ให้ใช้งานได้สะดวก
- สร้าง Dropdown List กับสิ่งที่ต้องใช้ซ้ำๆ
- Combine Data
- สร้าง Pivot Table เช็คสุขภาพการเงิน
- Dimension vs. Measurement
- How to build a PIVOT TABLE?
- จำนวนรายรับ-รายจ่ายทั้งหมดที่เกิดขึ้นในบัญชี
- โดยเฉลี่ยเราได้เงินและใช้จ่ายต่อเดือนอยู่ที่เท่าใด
- วันไหนที่มีค่าใช้จ่ายรวมมากที่สุด
- แนวโน้มรายรับ-รายจ่ายแต่ละเดือนเป็นอย่างไร
- คำนวณรายรับ-รายจ่ายรวมแบ่งตาม CATEGORY
- คำนวณรายรับ-รายจ่ายรวมแบ่งตาม PAYMENT_METHOD
- Build Dashboard in GGSheets
- Looker Studio (Optional)
- Epilogue
- More posts
สร้างชีทใหม่ภายใน 5 วินาที
เริ่มต้นด้วยการเปิดเว็บ browser ขึ้นมา แล้วพิมพ์ sheets.new ในช่อง URL

ปล.ให้เวลา 2 วิในการพิมพ์ ส่วนอีก 3 วิเป็นเวลาที่เน็ตโหลดหน้าขึ้นมา 5555555++
ตั้งชื่อชีทใหม่
เวลาเราสร้างอะไรใหม่ๆอย่าลืมตั้งชื่อกันนะ เวลาพูดถึงเค้าจะได้จำได้ ก็เหมือนกับคนที่เราอยากรู้จักเราก็มักจะจำเค้าได้ดีจากชื่อและหน้าตา เดี๋ยววววววววววว..
เอาเมาส์ไปคลิกที่ชื่อข้างๆโลโก้ Google Sheets แล้วพิมพ์ชื่อได้เลย

แบ่งชีทให้ชัดเจน
จะเห็นว่า แถบข้างล่างของ Google Sheets เราสามารถเพิ่มชีทสำหรับแบ่ง table ออกเป็นส่วนๆได้ เพื่อให้งานของเราเป็นระบบมากยิ่งขึ้น

ดังนั้น เราจะแบ่งบัญชีรายรับ-รายจ่ายนี้ออกเป็น 4 ส่วน ได้แก่
- INCOME = บัญชีรายรับ
- EXPENSE = บัญชีรายจ่าย
- COMBINED_DATA = ชีทสำหรับรวมข้อมูลรายรับ-รายจ่ายเพื่อทำ pivot table
- DASHBOARD = ชีทรวมกราฟและแผนภูมิต่างๆในการสรุปสุขภาพการเงินของเรา สำหรับการวิเคราะห์ insights ที่ได้จากบัญชีของเรา (ปล่อยน้องเป็นหน้าเปล่าๆไปก่อน แบบทิ้งไว้กลางทาง – Potato 55555)
ตั้งชื่อ header ให้บัญชีรายรับรายจ่าย
การตั้งชื่อ header ในบัญชีรายรับรายจ่ายสำคัญมากๆ เหมือนเราวางโครงสร้างบ้านเราให้มั่นคง ของเราจะสร้างทั้งหมด 8 header ให้กับชีท INCOME กับ EXPENSE ก่อน ทุกคนสามารถเพิ่มเติมจากนี้ได้นะ
- INCOME_ID/EXPENSE_ID = ลำดับที่รายการเงินเข้า-ออก
- DESCRIPTION = รายละเอียดของรายการเงินเข้า-ออก (เหมือน note ในสลิปธนาคาร)
- LOCATION = สถานที่ที่ได้รับเงินหรือเสียเงิน
- CATEGORY = ประเภทของรายรับ-รายจ่าย เช่น ค่าอาหาร, ค่าเดินทาง
- PAYMENT_METHOD = ช่องทางการรับเงิน-จ่ายเงิน เช่น เงินสด, บัญชีกสิกร, บัตรเดบิต, บัตรรถไฟฟ้า
- DATE = วันที่รับเงิน-จ่ายเงิน (แนะนำให้ใช้ format: YYYY-mm-dd)
- AMOUNT = จำนวนเงินที่ได้รับมา-จำนวนเงินที่จ่ายไป (บาท)
- SOURCE = ที่มาของ transaction นั้นๆว่าเป็น INCOME หรือ EXPENSE
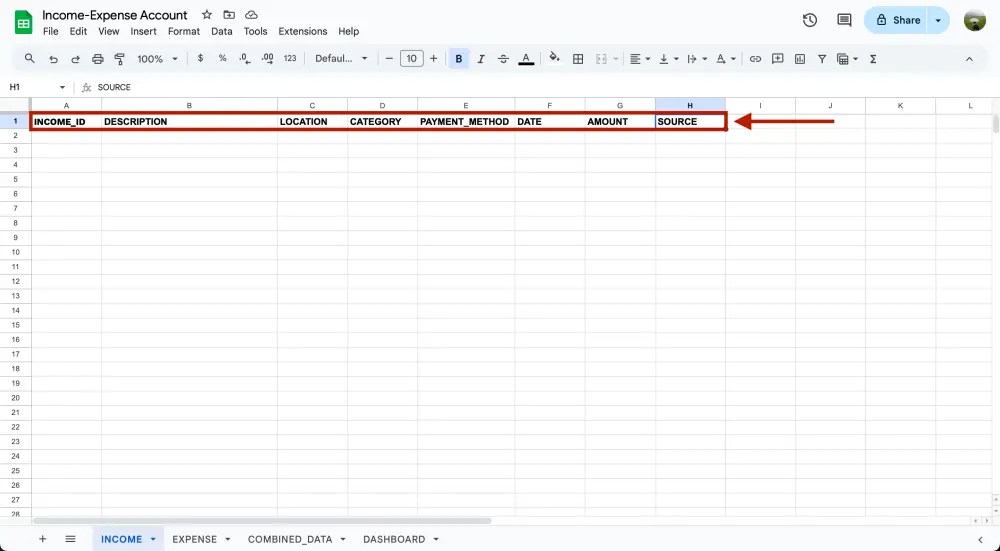
ตัวอย่างชีทรายรับ 2024
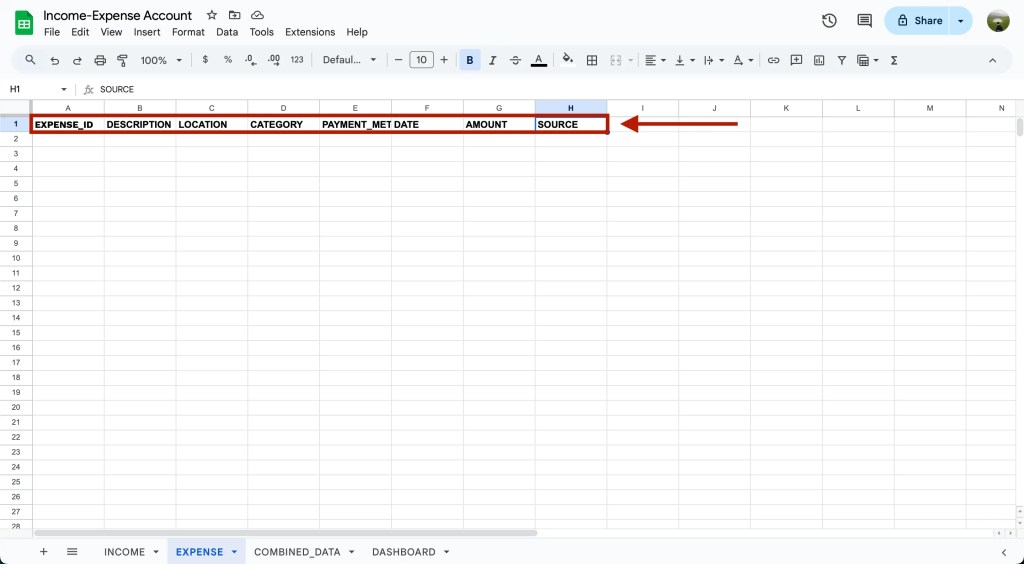
ตัวอย่างชีทรายจ่าย 2024
Additional Tips!
เรามี trick เล็กๆน้อยๆสำหรับการรันตัวเลข ID และใส่คำซ้ำในทุกๆแถวมาฝาก สำหรับสายขยันที่ไม่อยากเสียเวลากับงานที่ต้องทำซ้ำๆ
เราขอแนะนำ 3 ฟังก์ชันที่จะมาช่วยแก้ปัญหานี้กันก่อน นั่นคือฟังก์ชัน IF จะรับ input 3 ตัว
- logical_expression = เงื่อนไขที่คอยเช็คคนๆนี้ (cell) ว่าจะผ่านด่านตรวจมั้ย
- value_if_true = ผลที่จะตามมาหากคนๆนี้ทำตามกฎ
- value_if_false = ผลที่ตามมาหากคนๆนี้ไม่ทำตามกฎ
นี่มันฟังก์ชันผู้คุมกฎชัดๆ

ฟังก์ชันที่ 2 คือ ISBLANK สำหรับเช็คว่า cell นั้นเป็นช่องว่างหรือไม่
- ถ้า cell นั้นว่าง แล้ว จะ return เป็นค่า TRUE
- ถ้า cell นั้นไม่ว่าง แล้ว จะ return เป็นค่า FALSE
และฟังก์ชันสุดท้ายคือ ROW สำหรับ return เป็นตัวเลขที่บอกว่า cell นั้นอยู่แถวที่เท่าไหร่
ทุกอย่างก็พร้อมแล้ว เราจะมารันเลขในคอลัมน์ ID กัน
เริ่มแรก ให้เราพิมพ์สูตรนี้เข้าไปที่ cell A2
=IF(ISBLANK(F2:F)=FALSE,ROW(A2:A)-1,"")ภายในฟังก์ชัน IF เราสร้างเงื่อนไขว่า
- ถ้า แถวไหนในคอลัมน์ DATE ไม่เป็นช่องว่าง แล้ว ให้นำลำดับที่ของแถวนั้นลบ 1
เช่น ROW(A2) จะ return เป็นเลข 2 แต่ในตารางต้องระบุเป็นเลข 1 จึงต้องลบ 1 ด้วย - ถ้า แถวไหนในคอลัมน์ DATE เป็นช่องว่าง แล้ว ให้ cell นี้เป็นช่องว่างเหมือนเดิม
จากนั้นให้เรากดปุ่ม command + shift + enter ใน keyboard เพื่อ apply function ArrayFormula ให้สูตรนี้รันเป็น array

ส่วนคอลัมน์ SOURCE ใน cell H2 เราแค่แก้จาก ROW(A2:A)-1 เป็น “Income” (“Expense”) ได้เลย
คำเตือน!! ตัวช่วยนี้จะใช้ได้ ก็ต่อเมื่อ เราชัวร์ว่าคอลัมน์ที่เราใส่ในฟังก์ชัน ISBLANK จะมีข้อมูลอยู่ครบทุกแถวจริงๆ
ทีนี้เราลอง test ว่าใช้ได้จริงมั้ย โดยการพิมพ์วันที่ใน cell F2 ดูกัน ถ้า cell A2 ขึ้นเป็นเลข 1 และ cell H2 ขึ้นเป็นคำว่า Income แสดงว่าใช้ได้

ตั้งค่า column วันที่ให้ใช้งานได้สะดวก
Pain point หนึ่งเลยที่เวลาคนกรอกข้อมูลที่เป็นวันที่ น่าจะเจอปัญหาเรื่อง format ของวันที่ ที่แต่ละคนเข้าใจจะไม่ตรงกัน โดย format มาตรฐานที่แนะนำจะเป็น YYYY-mm-dd
ขั้นตอนแรก ให้เราเอาเมาส์ไปคลิกที่ cell F2 จากนั้นกด Command + Shift + Arrow Down เพื่อ highlight cell F2 เป็นต้นไป ไม่รวม header
Note: ใครใช้ Windows ให้เปลี่ยนจาก Command เป็น CTRL
ขั้นตอนต่อไป ให้ไปที่แถบเมนู (menu bar) คลิก Data > Data validation จากนั้นจะขึ้นหน้าต่าง Data validation rules ขึ้นทางขวามือ
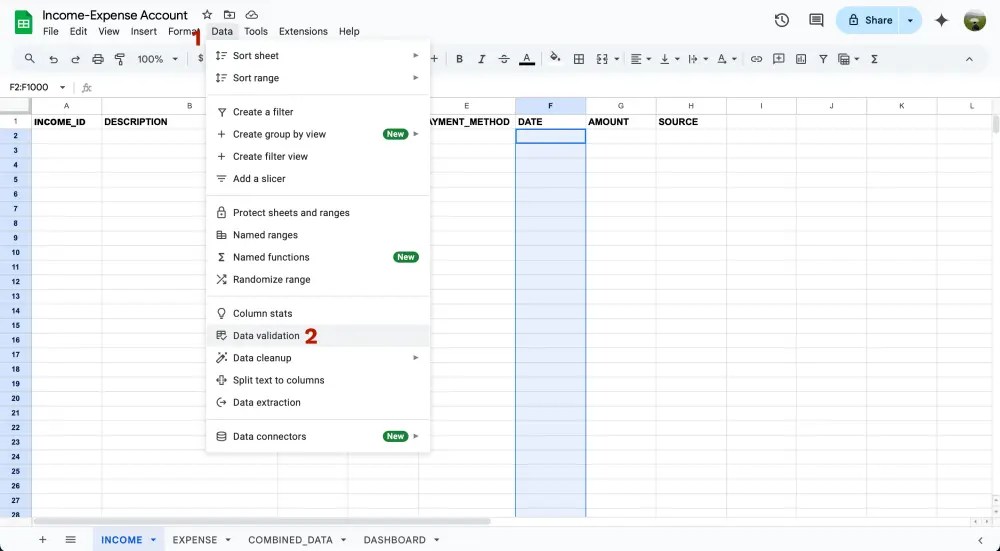
ขั้นต่อไป กด + Add rule จะขึ้นช่อง Apply to range และ Criteria ขึ้นมา

- Apply to range = ขอบเขตของ cell ที่เราจะ apply rule ที่เราสร้าง
- criteria = rule ที่เราจะสร้าง ในขั้นตอนนี้เราจะเลือกเป็น is valid date เพื่อให้แน่ใจว่าวันที่นี้มีอยู่จริง ถูกต้อง และ cell ที่เราสร้าง rule นี้ขึ้นมาก็จะกลายเป็นวันที่ทั้งหมด ทำให้เวลาเรากรอกวันที่ จะโชว์เป็นปฏิทินที่เราสามารถคลิกเลือกวันที่ได้เลย
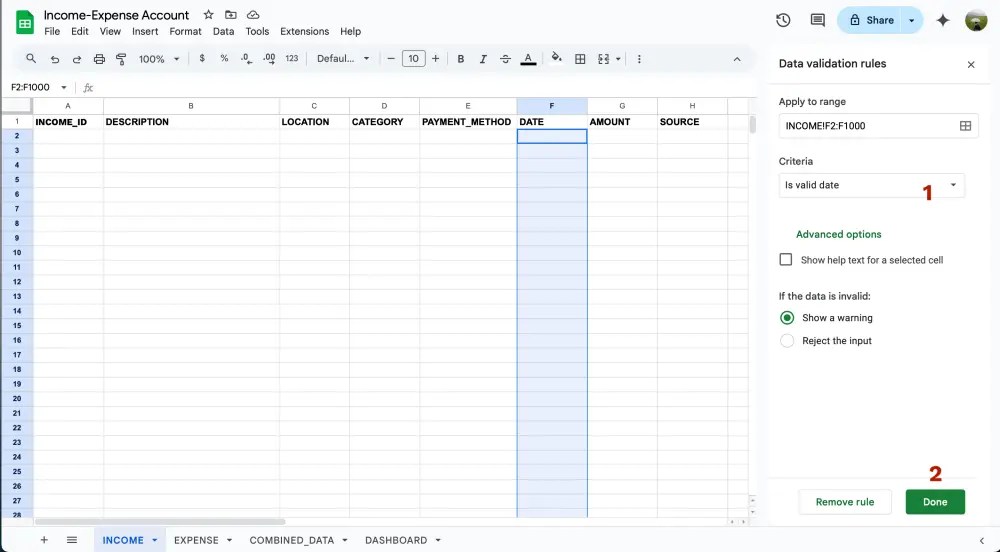
แต่หากเราลองเล่นดูจะพบว่า.. อ่าว เฮ้ยยยย ไม่เหมือนที่คุยกันไว้นี่หน่าาา 555555 เดี๋ยวนะ วันที่ยังไม่เปลี่ยนเป็น format ที่เราต้องการเลย

ให้ทุกคน highlight cell F2 เป็นต้นไปเหมือนเดิม จากนั้นสังเกตที่แถบเครื่องมือคลิกที่ 123 (More formats) > Custom date and time
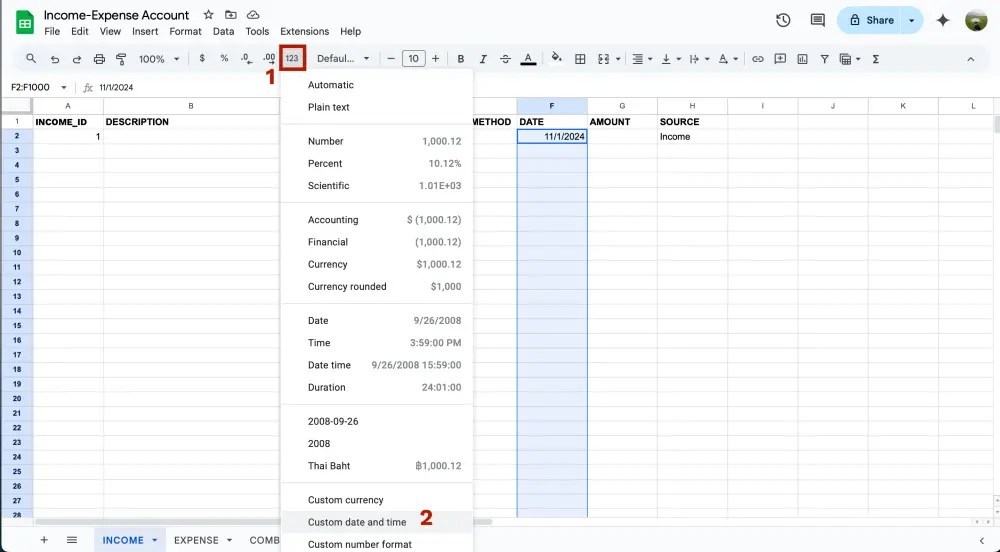
ในช่องซ้ายมือข้างปุ่ม Apply ให้เปลี่ยนตามนี้เลย โดยแต่ละอันคั่นด้วยเครื่องหมาย –
- Year = Full numeric year (1930)
- Month = Month with leading zero (08)
- Day = Day with leading zero (05)
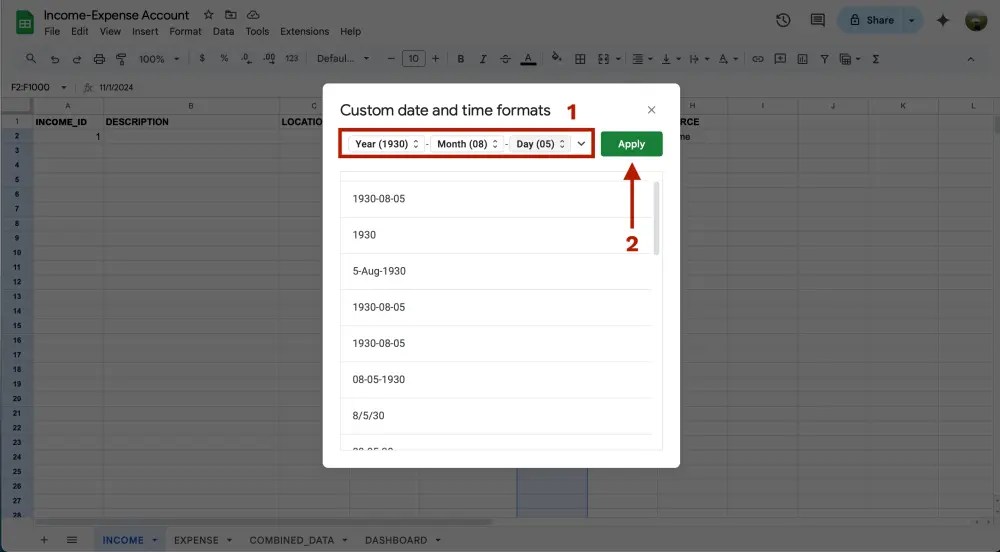
เสร็จแล้วกด Apply ได้ แค่นี้ก็เสร็จเรียบร้อยยยยยย
จากนั้นก็ทำแบบเดียวกันกับชีทรายจ่ายด้วยนะ อย่าลืมเชียว!!
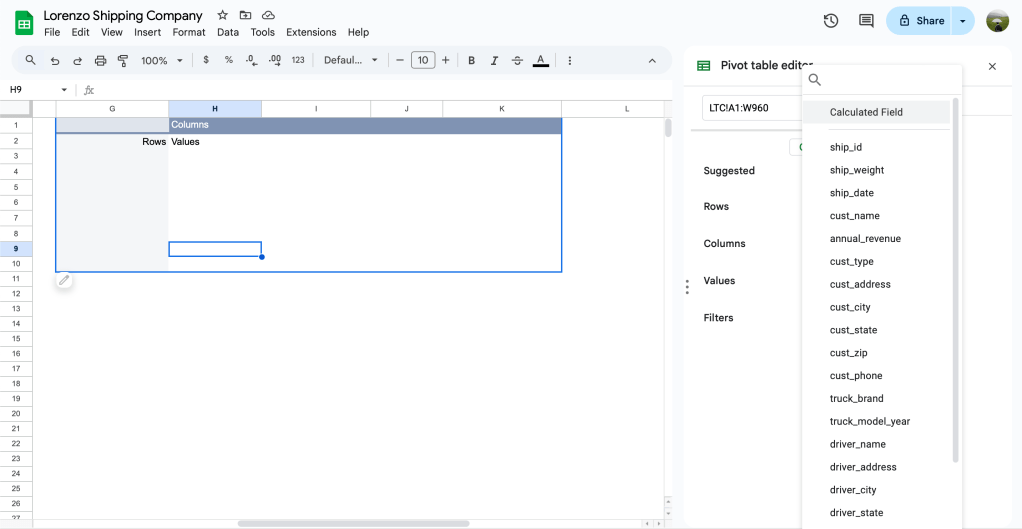
สร้าง Dropdown List กับสิ่งที่ต้องใช้ซ้ำๆ
ข้อมูลบาง column เราอาจจะต้องมีการพิมพ์ซ้ำอยู่บ่อยๆใช่มั้ย อย่างในเคสนี้ก็เป็นคอลัมน์ CATEGORY กับ PAYMENT_METHOD ที่จะมีการเรียกใช้ซ้ำทุกวัน
ดังนั้นเราจะมาสร้าง dropdown list เพื่อที่เราสามารถมาคลิกกดเลือกได้แบบสบายๆ โดยในตัวอย่างนี้เราจะทำให้ดูเฉพาะชีทรายรับนะครับ
ขั้นตอนแรก ให้เรา highlight cell D2 เป็นต้นไป จากนั้นสังเกตที่แถบเมนูเลือก Insert > Dropdown

จะมีหน้าต่าง Data validation rules ขึ้นมาทางขวามือ
- Apply to range = ขอบเขตที่เราจะใช้ dropdown นี้
- Criteria = เลือกเป็น Dropdown จากนั้นใส่ตัวเลือกที่เราต้องใช้บ่อยๆ
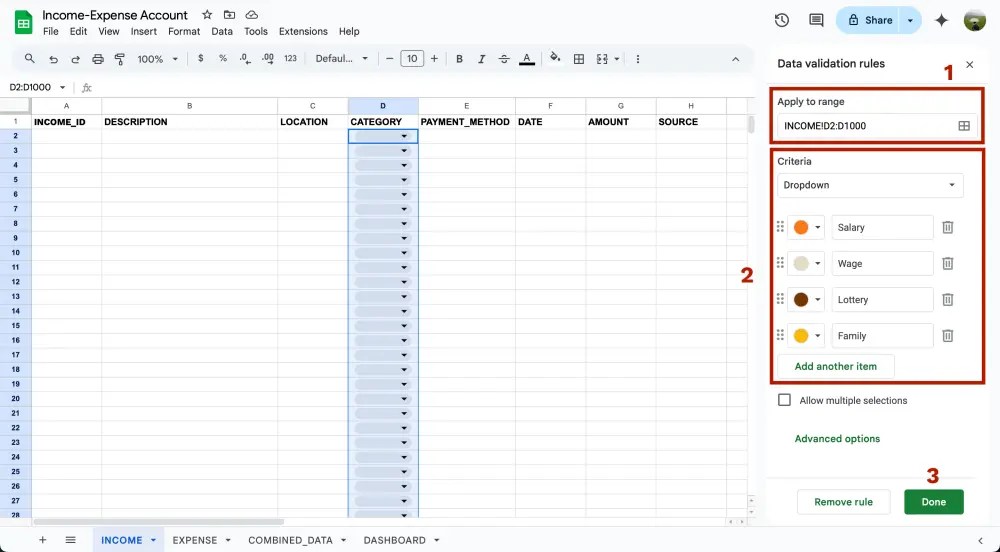
ตัวอย่าง dropdown list ของคอลัมน์ CATEGORY ในชีท INCOME
ใน column PAYMENT_METHOD ก็ทำแบบเดียวกันเลย

ตัวอย่าง dropdown list ของคอลัมน์ PAYMENT_METHOD ในชีท INCOME

ตัวอย่าง dropdown list ของคอลัมน์ CATEGORY ในชีท EXPENSE
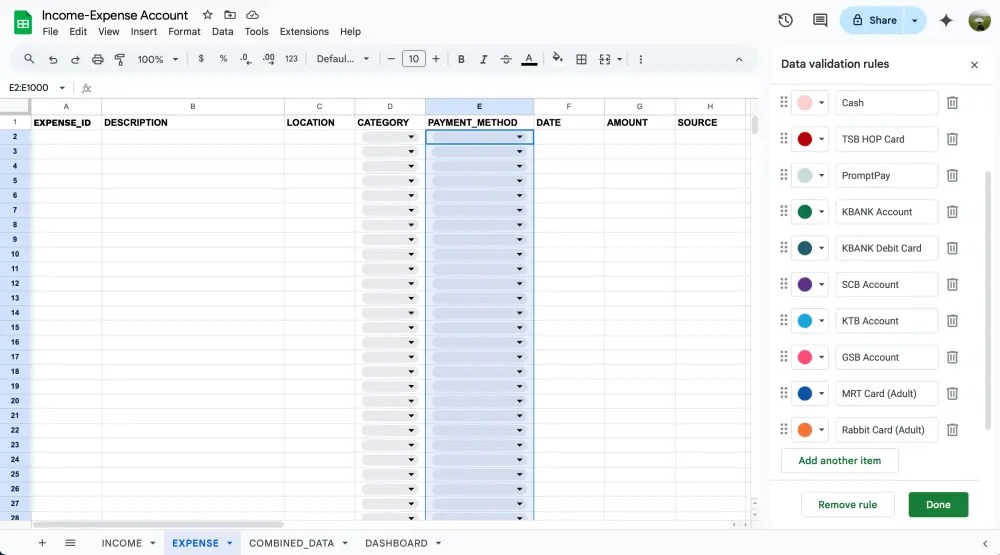
ตัวอย่าง dropdown list ของคอลัมน์ PAYMENT_METHOD ในชีท EXPENSE
Combine Data
เราจะ combine data ทั้งรายรับและรายจ่ายเข้าด้วยกันเป็น 1 sheet เพื่อที่เราจำสามารถสร้าง pivot table ที่นำตัวเลขรายรับ-รายจ่ายมาคำนวณได้
QUERY
มาแล้ว!! พระเอกของงานนี้ที่จะช่วยเราดึงข้อมูลให้มารวมไว้ที่เดียว นั่นคือ ฟังก์ชัน QUERY ซึ่งจะรับ input หลักๆอยู่ 2 ตัว คือ
- data = ข้อมูลที่เราต้องการดึง
- query = เป็นเหมือนคำถามที่เราถามกับ data ว่าต้องการข้อมูลส่วนไหนบ้าง ซึ่ง syntax จะคล้ายกับการเขียน SQL เลย

VSTACK vs. HSTACK
ถ้ามีแค่ชีทเดียวเราก็ใช้ QUERY ได้แบบสบายๆเลย แต่งานนี้ไม่ง่ายเท่าไหร่ ถ้าไม่ได้นางเอกอย่าง ฟังก์ชัน VSTACK และ HSTACK มาช่วย
สองฟังก์ชันนี้ทำหน้าที่เป็นเหมือนกาวที่ใช้เชื่อมหลายๆตารางเข้าด้วยกัน โดย VSTACK ใช้รวมตารางในแนวตั้ง และ HSTACK ใช้รวมตารางในแนวนอน ตามชื่อเป๊ะ!
เริ่ม Combine ได้!
ไปที่ชีท COMBINED_DATA แล้วสร้าง header ใน cell A1 ว่า TRANSACTION_ID จากนั้นใน cell A2 ใส่สูตรนี้เพื่อให้รันเลข ID แบบอัตโนมัติเหมือนกับชีทรายรับ-รายจ่าย
=IF(ISBLANK(F2:F)=FALSE,ROW(A2:A)-1,"")จากนั้นใน cell B1 เราจะพิมพ์สูตรนี้ลงไป
=QUERY(
VSTACK(
HSTACK("DESCRIPTION","LOCATION","CATEGORY","PAYMENT_METHOD","DATE","AMOUNT","SOURCE"),
HSTACK(INCOME!B2:H),
HSTACK(EXPENSE!B2:H)
), "select * where Col5 is not null")ในฟังก์ชัน QUERY เราจะอธิบายแยกเป็นสองส่วนให้เข้าใจง่ายๆนะ
- data = เราจะเริ่มใช้ VSTACK เพื่อให้ช่วงของข้อมูลทุกอย่าง stack กันเป็นคอลัมน์ก่อน จากนั้นเราถึงจะใช้ HSTACK เพื่อรวมข้อมูลที่เป็น header และข้อมูลในตาราง
– HSTACK อันที่ 1 เราใส่เป็น header
– HSTACK อันที่ 2 เราดึงข้อมูล INCOME ทั้งหมดด้วยการ refer ไปที่ชีท INCOME
– HSTACK อันที่ 3 เราดึงข้อมูล EXPENSE ทั้งหมดด้วยการ refer ไปที่ชีท EXPENSE - query = เราดึงข้อมูลทุกคอลัมน์จาก data โดยที่คอลัมน์ที่ 5 (DATE) ไม่มีค่า NULL
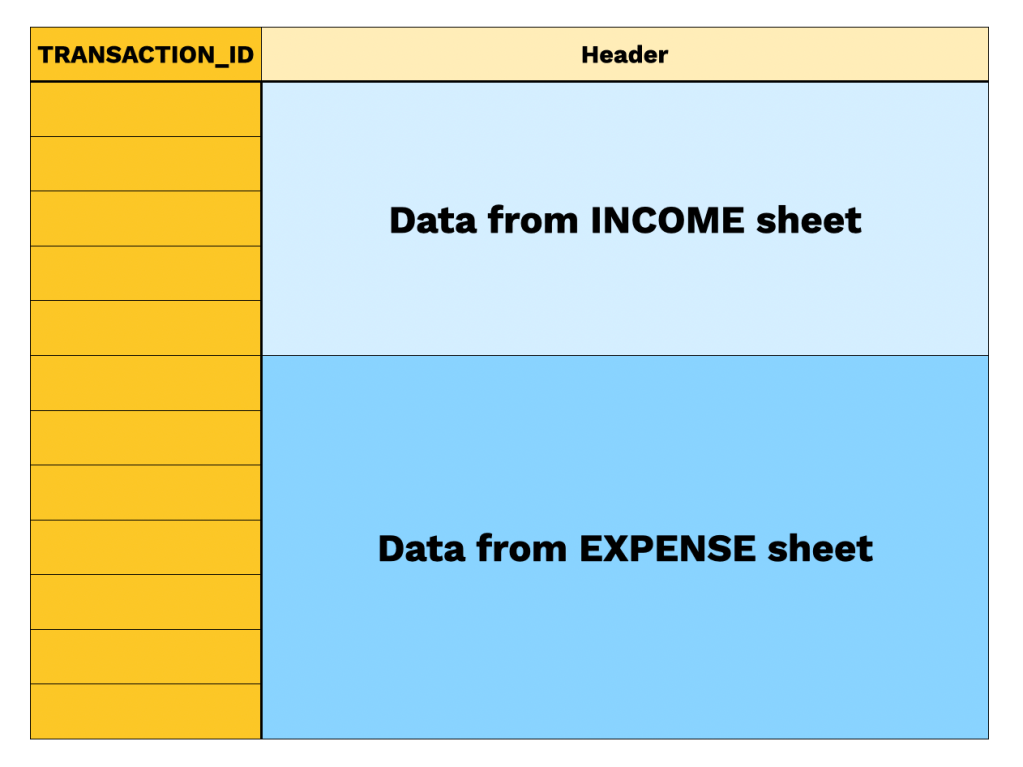
โครงสร้างข้อมูลของชีท COMBINED_DATA
เท่านี้เวลามีข้อมูลใหม่ๆเข้ามาจากชีท INCOME และ EXPENSE ในชีท COMBINED_DATA จะถูก update ให้อัตโนมัติเลย
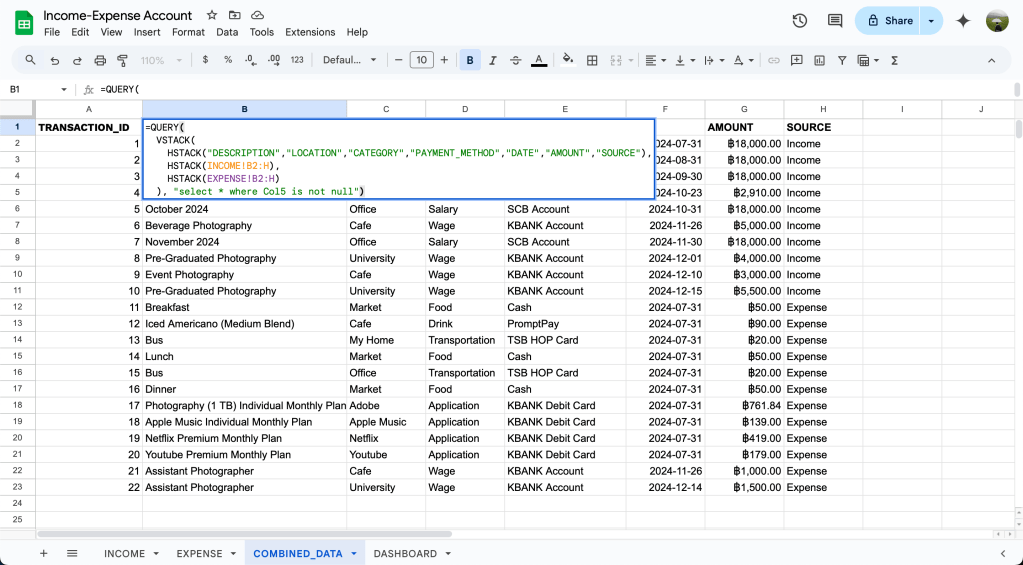
ตัวอย่างชีท COMBINED_DATA
สร้าง Pivot Table เช็คสุขภาพการเงิน
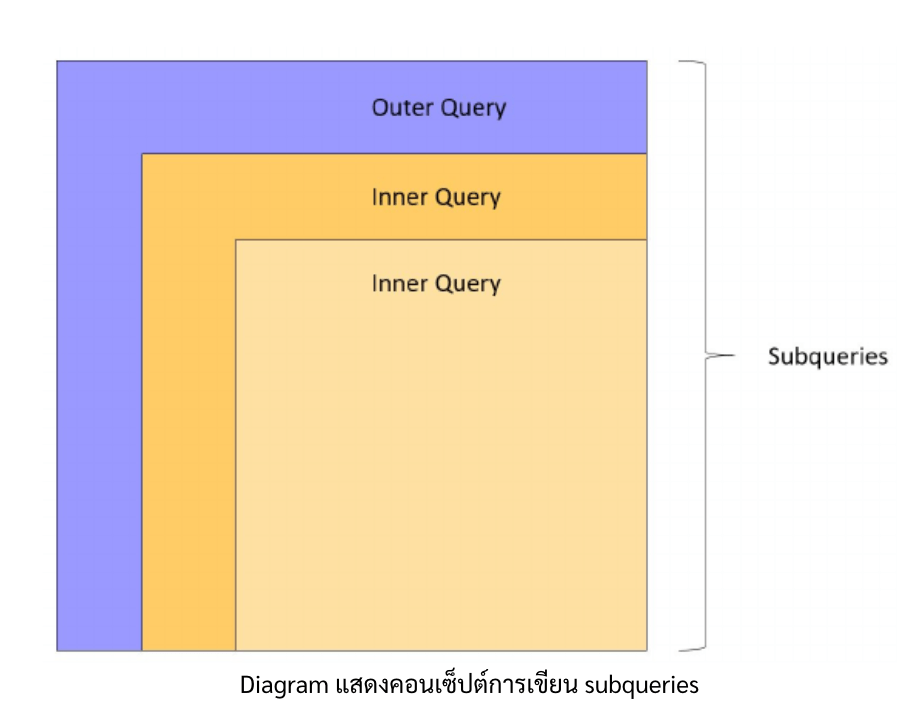
ถ้าพูดให้เข้าใจง่ายๆ Pivot Table คือ ตารางสรุปข้อมูลจาก raw data
โดยก่อนที่เราจะไปสร้าง pivot table กัน เรามา review คำศัพท์ใหม่สองคำนี้กันก่อนนะ
Dimension vs. Measurement
- Dimension คือ ข้อมูลที่เป็นจำพวก category ต่างๆ เช่น เพศ, กลุ่มลูกค้า, ชื่อเมือง
- Measurement คือ ข้อมูลที่เป็นตัวเลขที่สามารถคำนวณได้ในทางคณิตศาสตร์ ซึ่งต้องอ้างอิงกับหลักความเป็นจริง เช่น อายุ, ราคาสินค้า, จำนวนสินค้า, ระยะทาง
How to build a PIVOT TABLE?
เริ่มต้นจาก highlight ข้อมูลทั้งหมด แล้วไปที่แถบเมนูคลิก Insert > Pivot table
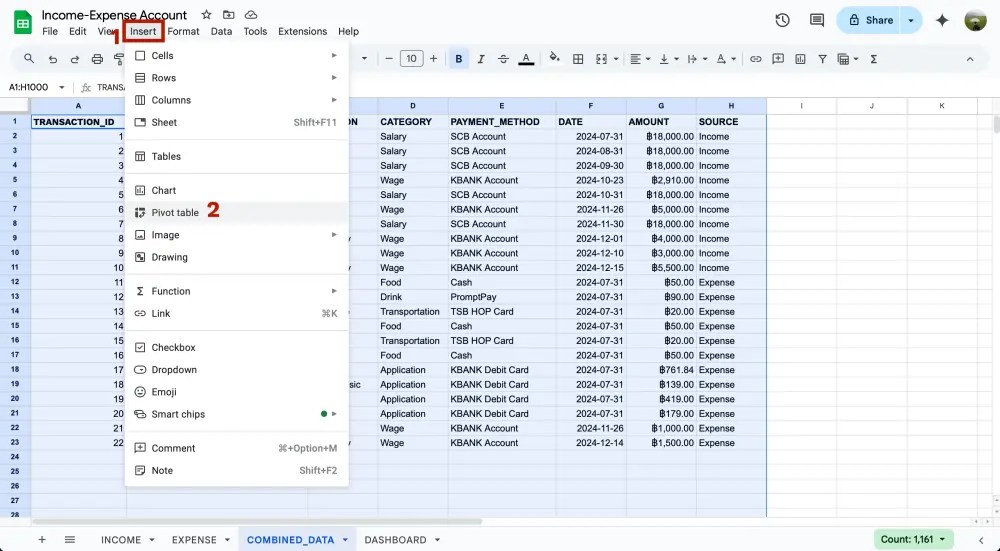
สังเกตว่าจะมีหน้าต่าง Create pivot table ขึ้นมาสำหรับเริ่มสร้าง pivot table
- Data range = ข้อมูลที่เราจะใช้สรุปผลเป็น pivot table
- Insert to = ชีทที่จะใช้โชว์ pivot table (ในตัวอย่างนี้เราเลือกเป็น New sheet)
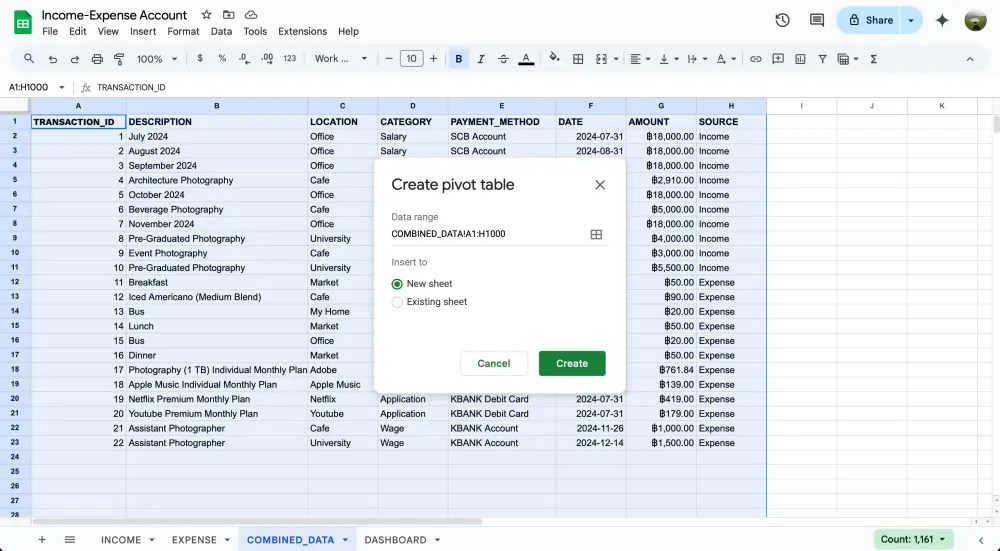
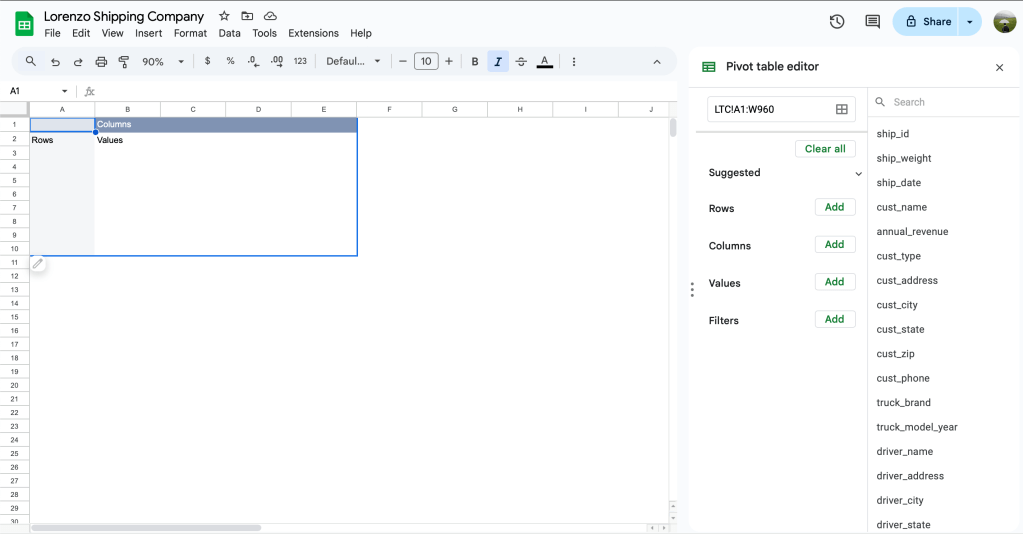
เสร็จแล้วกด Create ได้เลย แล้วจะมีหน้าต่าง Pivot table editor ขึ้นมาทางขวามือ ซึ่งจะแบ่งการทำงานออกเป็น 4 ส่วนให้เราต้องเข้าไปปรับแต่งกัน
- Rows = เราจะนำ dimension มาใส่ไว้เป็นตัวหลักของแถวใน column แรกของ table
- Columns = เหมือนกับ Rows เลยแต่จะเป็นส่วนขยายจาก column แรกอีกที
- Values = สิ่งที่สามารถวัดค่าได้เป็นตัวเลข ส่วนใหญ่จะเป็น measurement
แต่เราก็สามารถใส่ dimension ได้ แต่จะทำได้แค่การนับจำนวนข้อมูลเท่านั้น - Filters = กรองแถวสิ่งที่อยาก/ไม่อยากเห็นใน pivot table โดยการเขียนเงื่อนไข
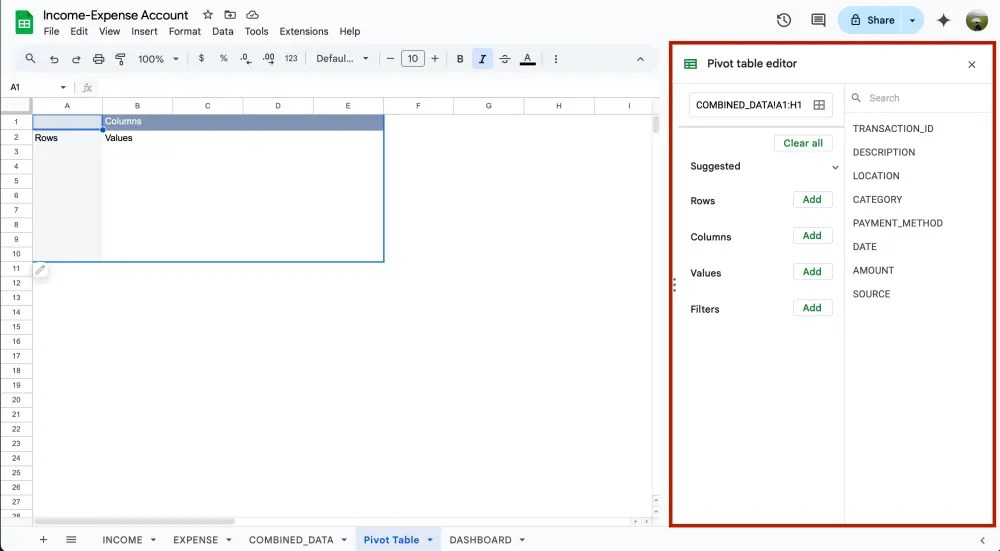
หากใครยังงงอยู่เรามีภาพให้ดูเข้าใจง่ายๆกัน

Pivot table diagram
***ข้อมูลที่เรานำมาใช้จะ mock up มาให้อยู่ในช่วงเดือนกรกฎาคม-ธันวาคม 2024 นะครับ
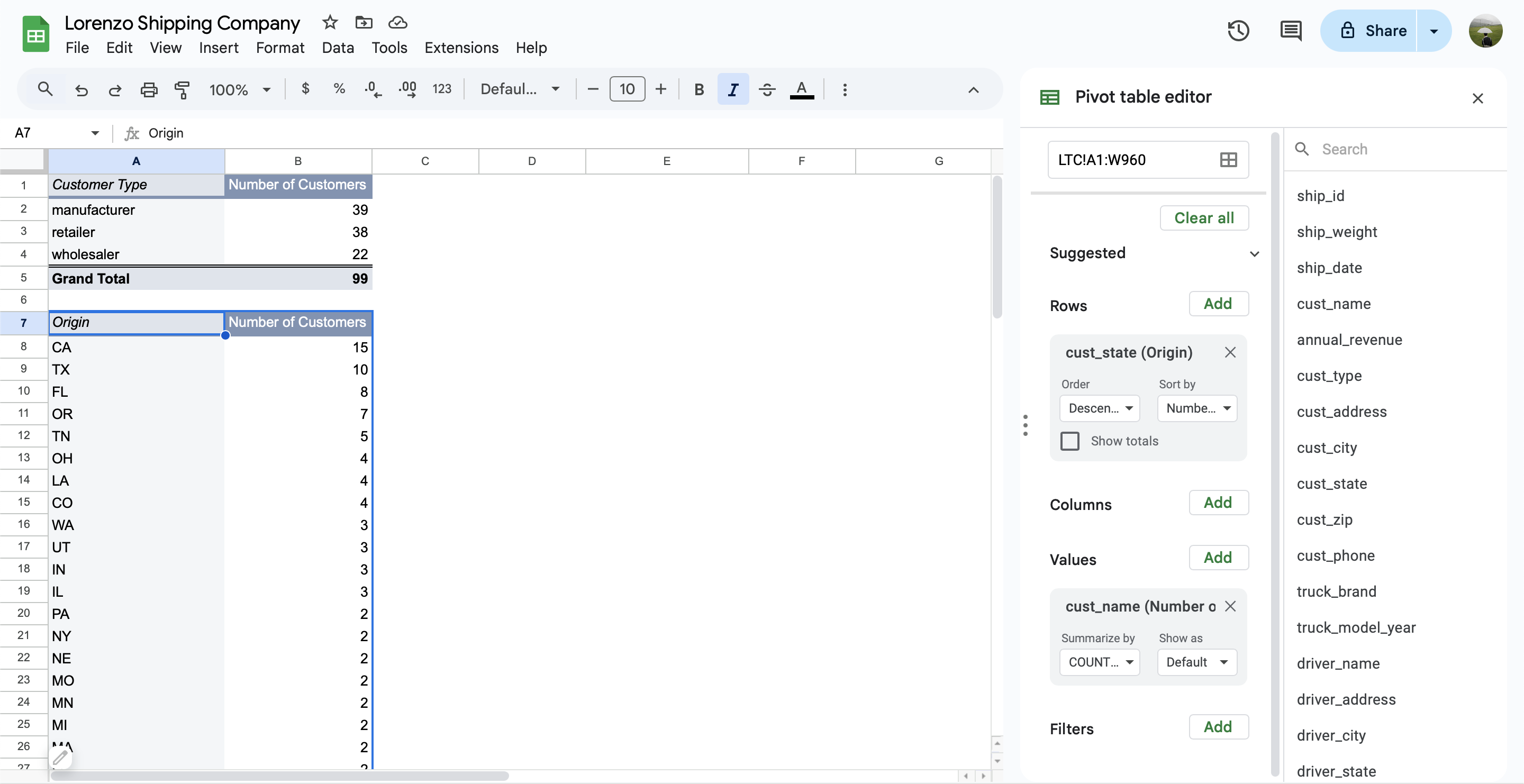
จำนวนรายรับ-รายจ่ายทั้งหมดที่เกิดขึ้นในบัญชี
เริ่มต้นจาก highlight ข้อมูล COMBINED_DATA ทั้งหมดก่อน
จากนั้นไปที่ INSERT > Pivot table โดยส่วนของ Insert to เลือกเป็น New sheet เพื่อสร้าง pivot table นี้ในชีทใหม่เลย (เราตั้งชื่อ sheet ใหม่เป็น PIVOT_TABLE)
- Values = AMOUNT ตั้งค่าเป็น SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Income เท่านั้น

Total Income report
Note: Data type ใน Google Sheets ประเภท Date จะเป็น Numeric ด้วย
ทีนี้ในการสร้าง report อันต่อๆไปให้เรา copy report ที่ทำก่อนหน้านี้มาแปะไว้ cell ที่ว่างๆแล้วสามารถเปลี่ยน Rows, Columns, Values, Filters ได้เลย
จากนั้น report ต่อไปให้เราตั้งค่าตามนี้ได้เลย
- Values = AMOUNT ตั้งค่าเป็น SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Expense เท่านั้น
สังเกตว่าเราแค่เปลี่ยน filter SOURCE จาก INCOME เป็น EXPENSE เท่านั้นเอง
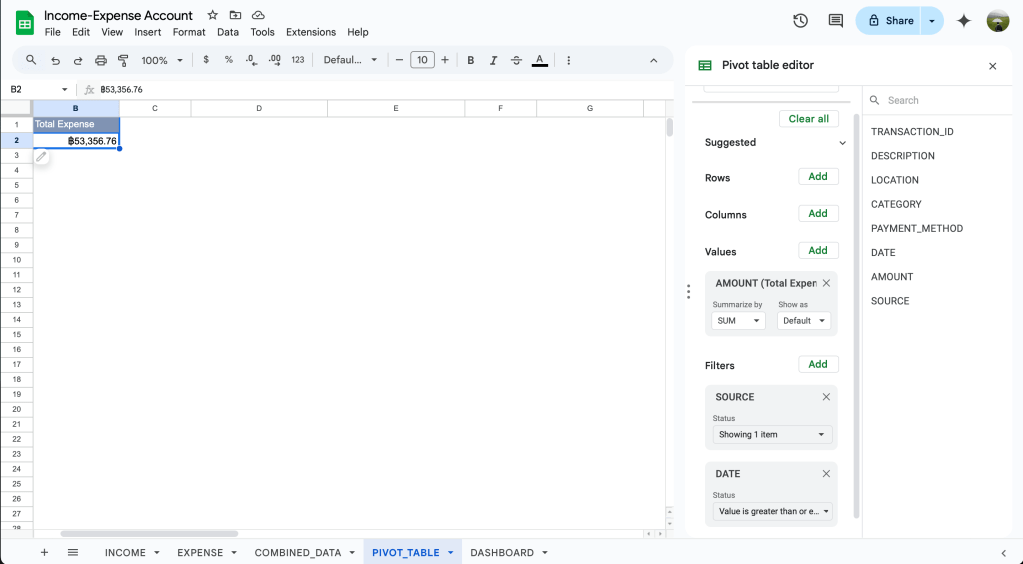
Total Expense report
ซึ่ง report รายจ่ายรวมจะอยู่ติดกับ report รายรับรวม เพื่อง่ายต่อการทำ bar chart ที่มี bar 2 อันให้ chart เดียว สำหรับเปรียบเทียบรายรับ-รายจ่ายรวมได้ชัดเจน

Total Income & Total Expense report
เห็นแบบนี้เราก็พอจะรู้ว่ามีเงินเหลือมั้ยหรือติดลบ แต่เราก็อยากจะมีตัวเลขตัวนึงมาช่วยให้เห็นภาพชัดเจนมากขึ้นใช่มั้ยว่า “สรุปแล้วเรามีรายรับหรือรายจ่ายมากกว่ากัน และเป็นอย่างไรเมื่อเทียบกับรายรับด้วย”
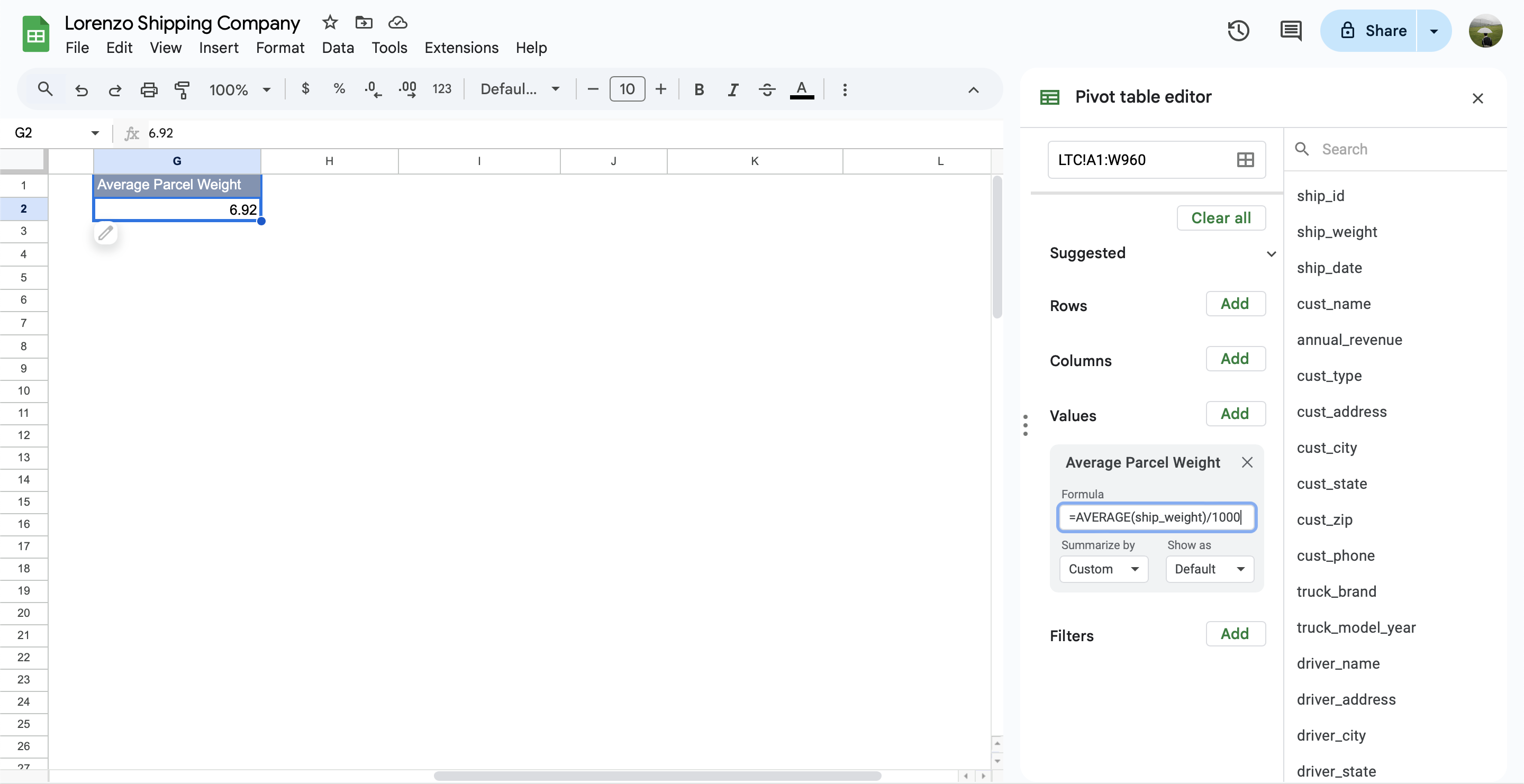
ตัวเลขตัวนั้นก็คือ อัตรากำไรสุทธิ (Net Profit Margin: NPM) นั่นเอง
NPM = (รายได้รวม - รายจ่ายรวม) / รายได้รวม- Values = เลือกเป็น Calculated Field แล้วพิมพ์สูตรตามที่เราวางแผนไว้
=(SUMPRODUCT(SOURCE = "Income", AMOUNT) -
SUMPRODUCT(SOURCE = "Expense", AMOUNT)
) / SUMPRODUCT(SOURCE = "Income", AMOUNT)- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล

Net Profit Margin report
Summarise: จาก transcation ทั้งหมดพบว่า ในขณะนี้มีรายจ่ายมากกว่ารายได้ถึง 8,846.76 บาท (คิดเป็น NPM อยู่ที่ -19.88%) ซึ่งสูงมากกกกกกก ในชีวิตจริงเราอยากเห็นตัวเลขนี้เป็นบวกให้ได้มากที่สุดเท่าที่จะทำได้
โดยเฉลี่ยเราได้เงินและใช้จ่ายต่อเดือนอยู่ที่เท่าใด
รายรับและรายจ่ายโดยเฉลี่ยต่อเดือนจะพอให้เราคาดการณ์ในภาพรวมได้ว่า สถานะตอนนี้เรามีรายได้-รายจ่ายมากกว่ากัน
โดยเราจะคำนวณรายได้เฉลี่ยและรายจ่ายเฉลี่ยได้จาก
รายได้ (รายจ่าย) เฉลี่ยต่อเดือน = รายได้รวม (รายจ่ายรวม) / จำนวนเดือนที่เก็บข้อมูล- Values = เลือกเป็น Calculated Field แล้วพิมพ์สูตรตามที่เราวางแผนไว้
## ใช้ IF เช็คก่อนว่าสูตรที่เราคำนวณเป็นเดือนเดียวกันหรือไม่ (ตัวหารในสูตรคำนวณค่าเฉลี่ยเท่ากับ 0 หรือเปล่า?)
= IF(MONTH(MAX(DATE)) - MONTH(MIN(DATE)) = 0,
SUM(AMOUNT),
SUM(AMOUNT) / ( MONTH(MAX(DATE)) - MONTH(MIN(DATE)) )
)- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Income เท่านั้น

Average Income per Month report
และการคำนวณรายจ่ายเฉลี่ยต่อเดือนก็ทำแบบเดียวกับรายได้เฉลี่ยต่อเดือนเลย
- Values = เลือกเป็น Calculated Field แล้วพิมพ์สูตรตามที่เราวางแผนไว้
## ใช้ IF เช็คก่อนว่าสูตรที่เราคำนวณเป็นเดือนเดียวกันหรือไม่ (ตัวหารในสูตรคำนวณค่าเฉลี่ยเท่ากับ 0 หรือเปล่า?)
= IF(MONTH(MAX(DATE)) - MONTH(MIN(DATE)) = 0,
SUM(AMOUNT),
SUM(AMOUNT) / ( MONTH(MAX(DATE)) - MONTH(MIN(DATE)) )
)- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Expense เท่านั้น

Average Expense per Month report
Note: เราใช้ AVERAGE คำนวณตรงๆไม่ได้เพราะตัวหารใน AVERAGE จะใช้เป็นจำนวน transaction ที่เกิดขึ้น (จำนวน row ทั้งหมด)
Summarise: จาก report พบว่า ในภาพรวมโดยเฉลี่ยรายรับน้อยกว่ารายจ่ายอยู่ 1,769.35 บาท ซึ่งเป็นสถานะที่ไม่ค่อยดีซักเท่าไหร่เลย
วันไหนที่มีค่าใช้จ่ายรวมมากที่สุด
Routine ของแต่ละคนใน 1 สัปดาห์ของใครหลายคนมักจะวน loop กันใช่มั้ย แล้วก็จะมีเหตุการณ์แบบวันนี้ของทุกสัปดาห์จะใช้เงินเยอะสุดเลย ดังนั้นเราจะมาเจาะในประเด็นนี้กัน
- Rows = DATE
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Expense เท่านั้น
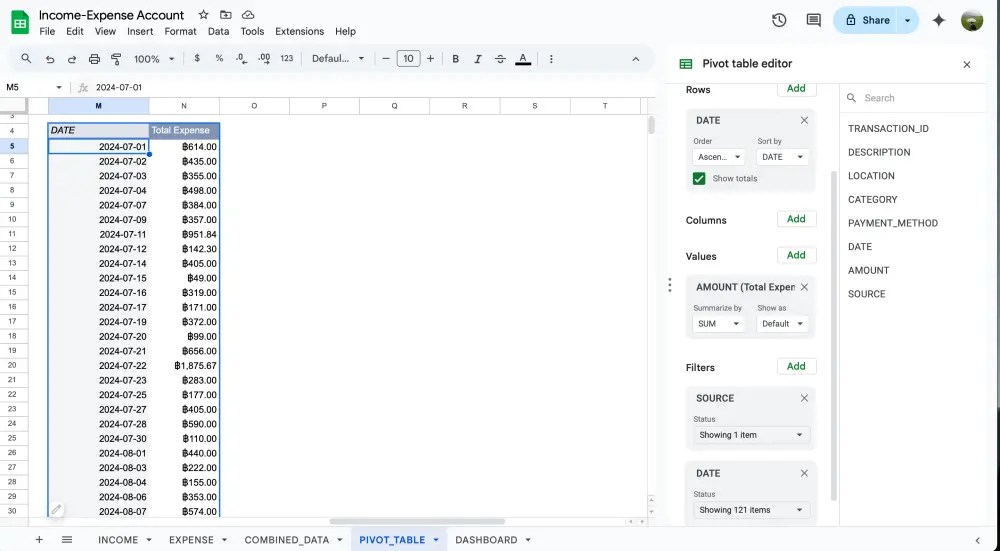
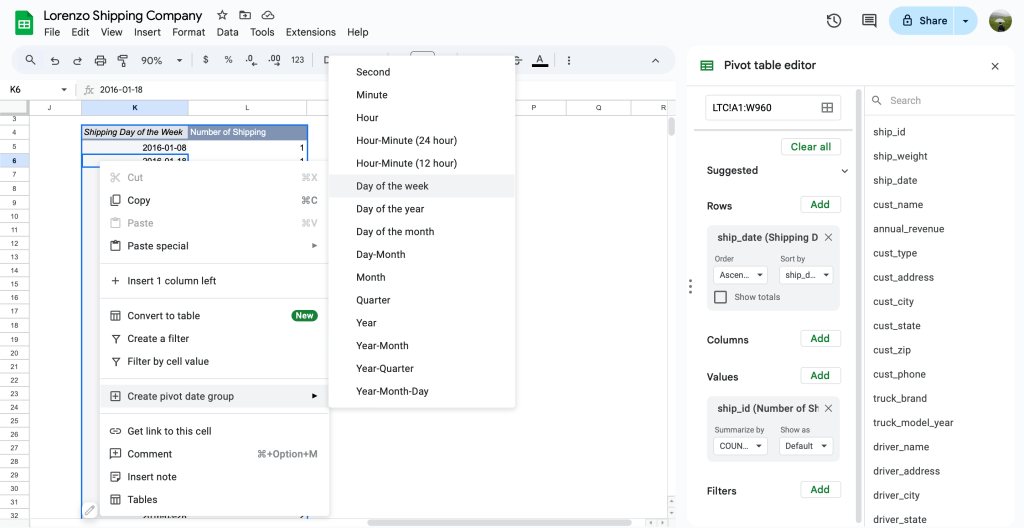
แต่สังเกตว่ารายรับ-รายจ่ายจะยังแยกเป็นรายวันอยู่ ซึ่งเราอยากดูเป็นวันในสัปดาห์เพื่อจะหา pattern หรือ insights บางอย่างจากการใช้จ่ายของเรา
ให้เราคลิกขวาตรงไหนก็ได้ในคอลัมน์ DATE แล้วเลือก Create pivot date group > Day of the week
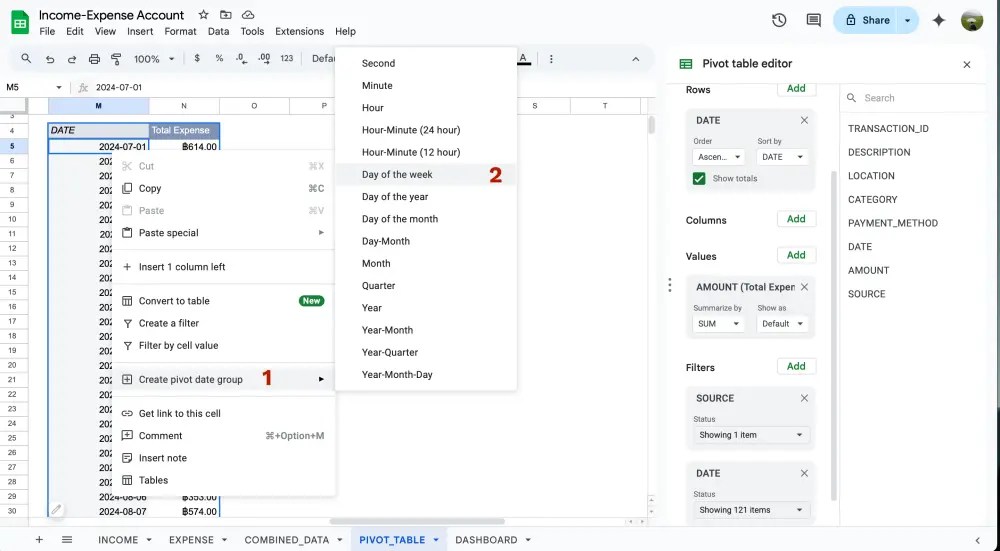
Create pivot date group > Day of the week

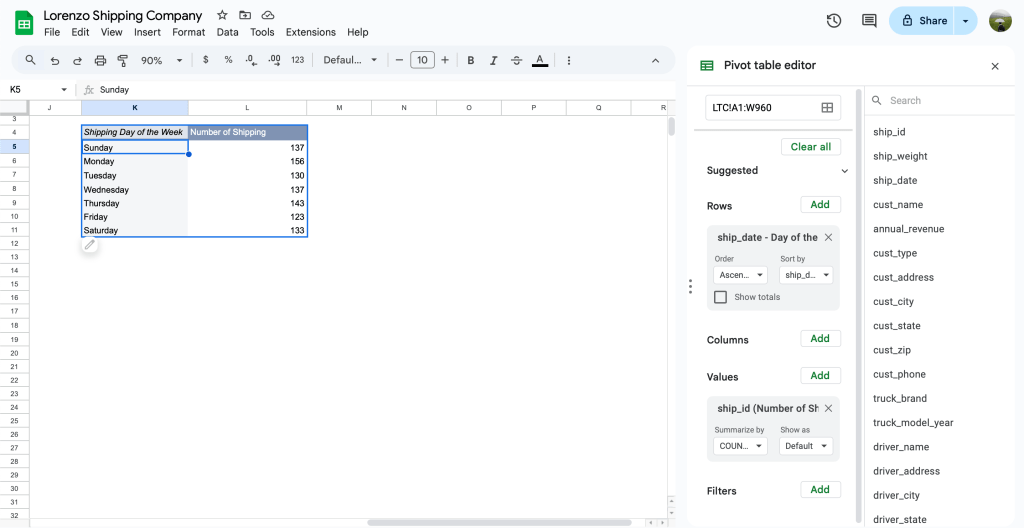
Total Expense by Day of the Week report
Summarise: จาก report จะเห็นว่า วันเสาร์เป็นวันที่มีการใช้เงินมากที่สุด รองลงมา คือ วันอังคารและวันอาทิตย์ ซึ่งพอจะคาดการณ์นิสัยได้ว่า วันเสาร์เป็นวันที่สามารถออกไปเที่ยวหรือไป hang out ดึกๆกับเพื่อนกับแฟนได้ ทำให้มีการใช้เงินที่ค่อนข้างเยอะกว่าวันอื่นๆ
เมื่อเรารู้แล้วว่าวันไหนเราใช้จ่ายเยอะเป็นอันดับต้นๆ เราอาจจะเจาะลึกไปได้อีกว่า activity ที่ทำให้เราเสียเงินมากขนาดนั้นเป็นเรื่องอะไร
แนวโน้มรายรับ-รายจ่ายแต่ละเดือนเป็นอย่างไร
ทุกวันนี้เรามีข้อมูลเงินเข้าเงินออกไหลเข้ามาจากที่ต่างๆเยอะมาก ทำให้เรามองด้วยตาเปล่าอาจจะไม่เห็น trend ที่ชัดเจน
ดังนั้น การสรุปรายรับ-รายจ่ายเป็นแบบ Time Series ก็จะช่วยเราทำนายรายรับ-รายจ่ายที่พอจะเป็นไปได้ในอนาคต
- Rows = DATE
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Income เท่านั้น
จากนั้นคลิกขวาตรงไหนก็ได้ในคอลัมน์ DATE แล้วเลือก Create pivot date group > Year-Month

Income Trend report
ในส่วนของรายจ่ายก็ทำแบบเดียวกันเลย เราแค่เปลี่ยน filter SOURCE เป็น Expense
- Rows = DATE
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Expense เท่านั้น
จากนั้นคลิกขวาตรงไหนก็ได้ในคอลัมน์ DATE แล้วเลือก Create pivot date group > Year-Month

Expense Trend report
แต่เนื่องจากเราจะทำ report นี้เป็น line chart ที่มีทั้งเส้นของ Total Income และ Total Expense ภายใน chart เดียวกัน
จึงจำเป็นที่เราจะต้องรวม report ทั้งสองอันนี้เป็น 1 report ด้วยการใช้ฟังก์ชัน QUERY โดยเราจะเลือกทุกคอลัมน์ยกเว้นคอลัมน์ R เพื่อให้ report เหลือแค่ 1 dimension และ 2 measurements
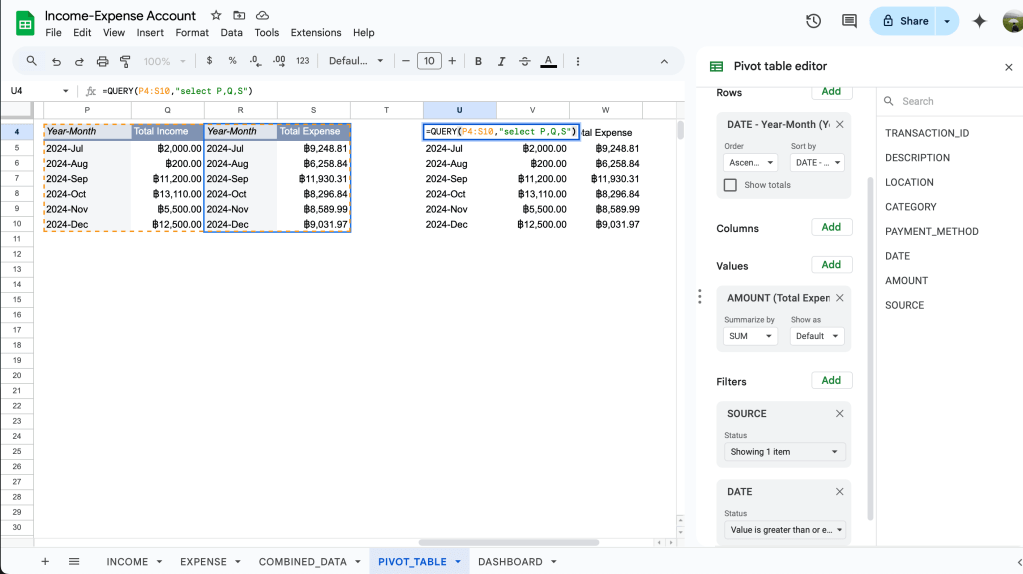
Summarise: จาก report จะเห็นว่าช่วง Q3 2024 (Jul-Sep 2024) สถานะการเงินค่อนข้างที่จะแย่มากๆเพราะมีรายจ่ายเยอะกว่ารายรับที่สูงมากๆ แต่พอถึงช่วง Q4 2024 (Oct-Dec 2024) สถานการณ์เริ่มกลับมาดีขึ้นบ้าง แต่ภาพรวมในครึ่งปีหลังค่อนข้างน่าเป็นห่วงสุดๆ
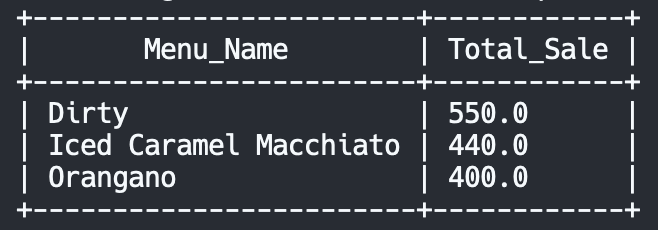
คำนวณรายรับ-รายจ่ายรวมแบ่งตาม CATEGORY
การที่เราเห็นรายรับของเราว่ามาจากแหล่งไหนบ้าง จะบ่งบอกถึงการทำงานของเราและ routine ในแต่ละวันของเราได้ประมาณนึงเลย
- Rows = CATEGORY ตั้งค่าให้ Total Income เป็นแบบ Descending
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Income เท่านั้น

Total Income by Category report
Summarise: จาก report พบว่า รายได้ส่วนใหญ่มาจากค่าจ้างและครอบครัวเป็นหลัก ซึ่งพอจะบอกได้ว่าคนๆนี้น่าจะทำอาชีพ freelance เพราะไม่มีรายได้จากเงินเดือนเลย
การแยกค่าใช้จ่ายเป็น category ให้ชัดเจนจะทำให้รู้ถึงพฤติกรรมการใช้ชีวิตของเราได้เป็นอย่างดีว่าเงินหมดไปกับอะไรมากเป็นอันดับต้นๆ
- Rows = CATEGORY ตั้งค่าให้ Total Expense เป็นแบบ Descending
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Expense เท่านั้น

Total Expense by Category report
Summarise: จาก report พบว่า ค่าใช้จ่ายส่วนใหญ่มาจากเครื่องดื่ม ซึ่งอาจจะเป็นค่ากาแฟหรือเครื่องดื่มบางอย่างกันนะ อันนี้ก็ไม่สามารถตอบได้ 100% 55555 อันดับที่ 2 คือ ค่าเดินทาง ซึ่งพอจะตอบคาดการณ์ได้ว่าบ้าน ที่ทำงาน หรือห้างอาจจะอยู่ไกลกัน และรองลงมา คือ ค่ากิจกรรมต่างๆ เช่น บัตรคอนเสิร์ต บัตรเข้าชมงาน
คำนวณรายรับ-รายจ่ายรวมแบ่งตาม PAYMENT_METHOD
ในส่วนนี้จะช่วยให้เรารู้ว่าควรบริหารจัดการบัญชีและเงินที่เข้ามาให้มีระบบได้อย่างไร
- Rows = PAYMENT_METHOD ตั้งค่าให้ Total Income เป็นแบบ Descending
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Income เท่านั้น
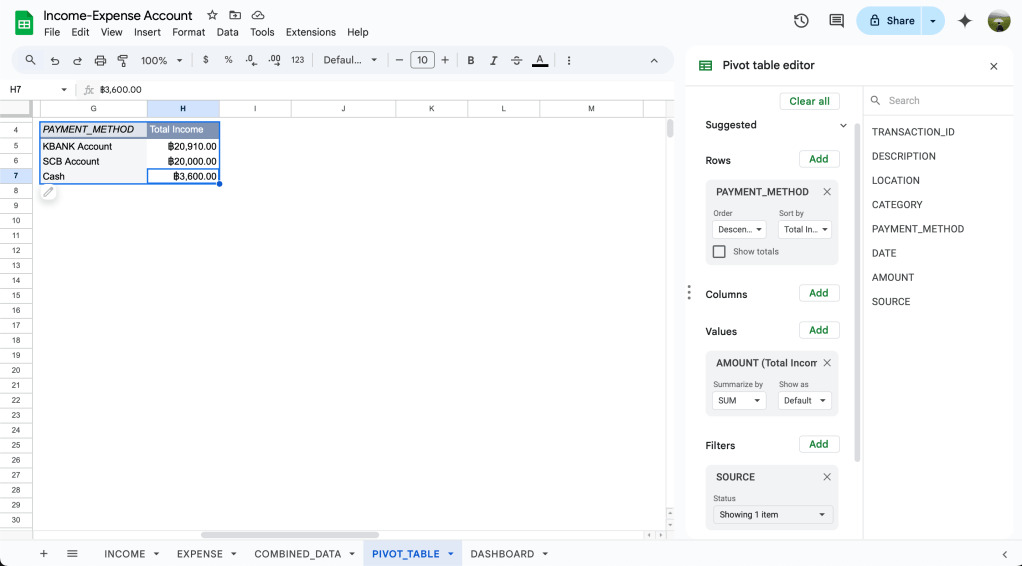
Total Income by Receive Method report
Summarise: จาก report นี้เห็นได้ชัดเลยว่ามีความเป็นไปได้สูงมากๆที่คนๆนี้จะรับค่าจ้างจากการทำงานมาจากบัญชี KBANK และเงินที่ได้จากครอบครัวจะเข้ามาจากบัญชี SCB เหมือนเริ่มตรวจสอบเส้นทางการเงินได้เลย เอ๊ะ! หรือว่าเราไปทำงานสรรพากรดีนะ 555555
และเราจะมาลองดูกันว่าเราใช้จ่ายเงินผ่านทางไหนมากที่สุดกัน!
- Rows = PAYMENT_METHOD ตั้งค่าให้ Total Expense เป็นแบบ Descending
- Values = AMOUNT ตั้งค่าเป็นแบบ SUM (หาจำนวนเงินรวมทั้งหมด)
- Filters = กรอง DATE ตั้งแต่วันที่เริ่มเก็บข้อมูล และ SOURCE เป็น Expense เท่านั้น

Total Expense by Payment Method report
Summarise: ดูจาก report นี้ก็พอตอบได้เลยว่าเงินของคนๆนี้จะออกง่ายมากถ้าที่ไหนมีพร้อมเพย์ ที่นั่นต้องมีเงินของเรา 5555 (อย่างกับสโลแกนประจำตัว) และเงินอีกก้อนส่วนใหญ่จะไหลออกมาจากบัญชี KBANK อีกช่องทาง
ข้อสังเกตของคนๆนี้ คือ รายจ่ายจากพร้อมเพย์ กับ รายจ่ายจากบัญชี KBANK (debit card + saving account) มีจำนวนเงินที่ค่อนข้างใกล้เคียงกันมากๆเลย
ซึ่งทำให้เราเห็นอะไรบางอย่างว่า การใช้งานพร้อมเพย์และแอพ KPlus (จาก KBANK) มีความสะดวกสบาย ใช้งานง่ายใน level เดียวกัน
อะไรก็ตามที่ดูใช้งานง่าย คนส่วนใหญ่มักจะใช้เพื่ออำนวยสะดวกให้ตัวเอง บัตรเดบิต บัตรเครดิตก็เช่นกัน 55555+
Build Dashboard in GGSheets
Dashboard คือ หน้าต่างแสดง chart ต่างๆจาก report หลายๆ chart มารวมให้อยู่ใน 1 หน้า สำหรับ monitor เฉพาะสิ่งที่ user ต้องการจะดูและ tracking ได้อยู่ตลอดเวลา เช่น KPI ที่บริษัทตั้งเป้าไว้, ลูกค้าที่ทำยอดขายสูงสุด, สินค้าตัวไหนขายดีสุด
The greatest value of a picture is
when it forces us notice what we never expected to see.John Tukey
คำกล่าวของ John Tukey เป็นสิ่งที่ยืนยันแล้วว่า รูปภาพมีพลังให้เรามองเห็นในสิ่งที่ไม่เคยอาจมองเห็นมาก่อน เหมือนเวลาเราอ่านหนังสือช่วงมหาลัย ถ้ามีแต่ text ยาวๆเราคงเข้าใจได้ยาก แต่ถ้าเป็นรูปภาพ เราจะจดจำได้ดี และเห็นความเข้าใจบางอย่างในเนื้อหานั้นได้
Chart ที่เราใช้ในการทำ dashboard นี้มีทั้งหมด 4 charts ที่ต้องมีทุกบ้าน ได้แก่
- Scorecard สำหรับแสดงตัวเลขสำคัญๆที่เห็นเป็นภาพรวม เช่น KPIs ของบริษัทตั้งไว้
- Pie chart เป็นกราฟวงกลมที่แบ่งสัดส่วนตาม dimension ที่มีไม่เยอะเกินไป
- Bar chart เป็นกราฟแท่งที่เหมาะกับการแสดงผลแบบเปรียบเทียบ
- Line chart เป็นกราฟเส้นแสดงตาม Timeline / Time Series
ขั้นตอนแรก ให้เรา highlight report ที่เราต้องการจะสร้าง chart จากนั้นไปที่แถบเมนูคลิก Insert > Chart

สังเกตว่า chart ของเราจะอยู่ในชีท PIVOT_TABLE แต่เราอยากได้ไปโชว์ในชีท DASHBOARD ใช่มั้ย
ให้เรากดสัญลักษณ์ 3 จุดที่มุมขวาของ chart แล้วเลือก Copy chart จากนั้นก็ลบ chart ในหน้าชีท PIVOT_TABLE ได้เลย
ย้ายตัวเองมาอยู่ที่ชีท DASHBOARD แล้วก็กดปุ่ม Command + V เพื่อวาง chart ได้เลย
ส่วนที่เหลือก็เป็นการปรับแต่ง chart ของตัวเองให้ดูเข้าใจง่าย ใช้สีไม่เยอะเกินไป โดยการไปที่ 3 จุดเหมือนเดิมแล้วเลือก Edit chart
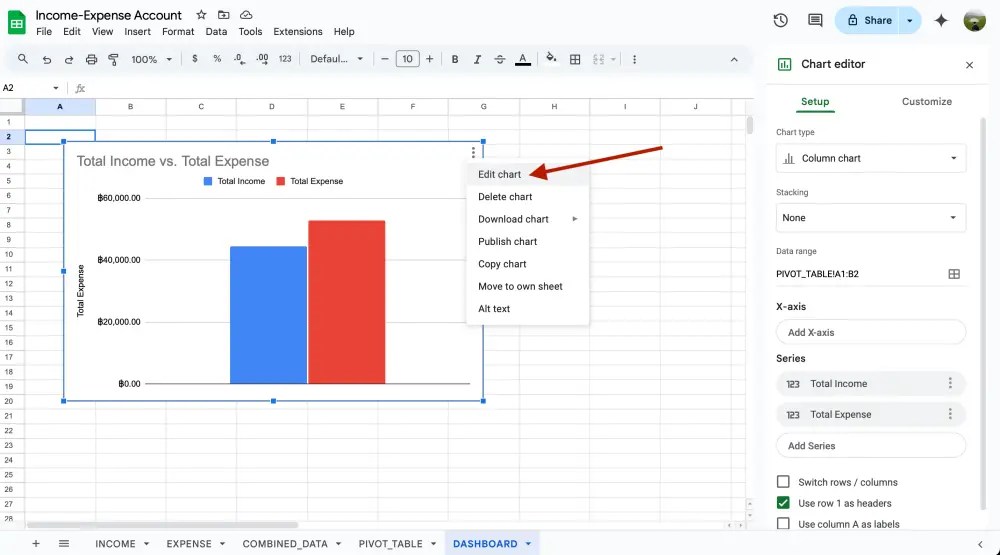
สังเกตว่าเมนูปรับแต่งแบ่งเป็น 2 ส่วน ได้แก่
- Setup = เลือก chart / ตั้งค่าว่าข้อมูลที่ใช้ทำ chart อยู่ที่ไหน
- Customize = ปรับแต่งได้ตั้งแต่ตัวกราฟเอง แกนของกราฟ ข้อความที่โชว์อยู่ ซึ่งเยอะมากจนทุกคนต้องลองเล่นเลย แต่อย่าเล่นเพลินจนลืมเป้าหมายที่เราทำ dashboard นะ
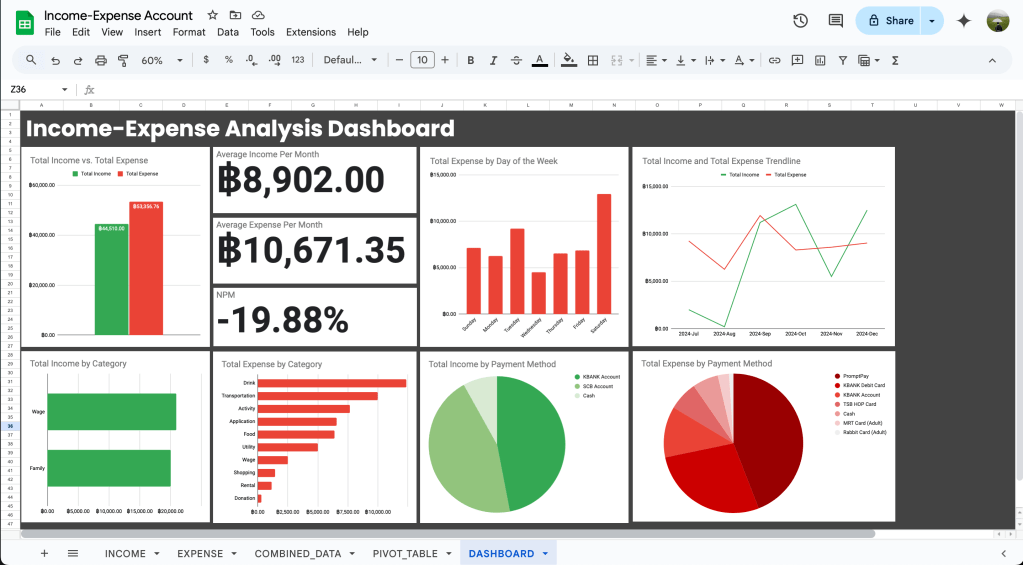
ตัวอย่าง Income-Expense Analysis Dashboard จาก Google Sheets
เห็นธีมสี dashboard ก็รู้เลยว่ากด public post ช่วงไหน 5555555
สิ่งสำคัญในการทำ dashboard คือ การจัดเรียงลำดับความสำคัญของ chart ว่าเราต้องการเล่าเรื่องราวให้ user ฟังแบบใดให้ตรงใจกับ business requirement
ซึ่งใน dashboard นี้เรากำลังจะเล่าว่า
- ในภาพรวม ณ ตอนนี้เรามีสถานะรายได้-รายจ่ายเป็นอย่างไร จาก dashboard เห็นชัดเลยว่า สถานะการเงินติดลบ มั้ยน้าาาาาาา T T
- ต่อมาเราก็มาลงรายละเอียดว่าในวันไหนเรามีรายจ่ายมากที่สุด เพราะ routine คนส่วนใหญ่ใน 1 สัปดาห์มักจะวนลูปเหมือนเดิม สังเกตว่าวันเสาร์มาแรงมาก อาจจะเป็นวันที่เราออกไปใช้เที่ยวเลยใช้เงินเยอะเป็นพิเศษ
- จากนั้นลองมาดูเทรนด์ในภาพใหญ่ว่าในแต่ละเดือนแนวโน้มรายรับ-รายจ่ายเป็นอย่างไร เดือนไหนที่ดูจะติดลบ (เส้นเขียวอยู่ต่ำกว่าเส้นแดง) ก็ไปดูต่อว่าเราจ่ายกับอะไรเยอะไปรึเปล่า หรือ หาเงินมาได้น้อยเกินไป หรือสามารถแบ่งดูเป็น quarter ได้
- หลังจากนั้นเรามาดูที่มาของรายได้-รายจ่ายของเราว่าส่วนใหญ่มาจากไหนเป็นอันดับต้นๆเพื่อควบคุมเงินของเรา สังเกตว่าในนี้ค่าเครื่องดื่มกับค่าเดินทางมาเยอะเชียว อาจจะเป็นเพราะหมดไปกับค่ากาแฟ บูสเอเนอจี้ในทุกๆวัน กาแฟมา งานเดิน 55555 หรืออาจจะเป็นค่าเครื่องดื่มบางประเภทกันนะ
- สุดท้ายก็มาดูว่ารายได้-รายจ่ายเราเข้า-ออกจากช่องไหนกันบ้างเพื่อบริหารบัญชีของเราให้ง่ายต่อการดูแลและควบคุมพฤติกรรมของใช้ของเราต่อไป สังเกตว่า PromptPay มาเป็นอันดับ 1 เลย แสดงว่าสแกนจ่ายง่าย เงินก็ออกง่ายเลยทีนี้
Looker Studio (Optional)
Looker Studio เป็นเครื่องมือสร้าง dashboard ที่ทรงพลังจาก Google ซึ่งเราสามารถ dashboard ได้ง่ายกว่า Google Sheets อีก ที่สำคัญคือใช้งานฟรีแค่มี Gmail
และเราว่าความพิเศษของ Looker Studio อยู่ที่การ import data ได้หลากหลายมาก ไม่ว่าจะเป็น Google Sheets, MS Excel, CSV file และอีกเยอะเลย แถมมีฟีเจอร์อย่าง Data freshness ด้วย
ในการสร้าง dashboard ไม่ว่าจะเป็น Google Sheets, Looker Studio, Tableau หรือ Power BI มีอยู่ด้วยกัน 3 step ง่ายๆเลยคือ Connect > Create > Share
Connect (Data)
ก้าวแรกสำคัญมาก ถ้าเราไม่มี data เราก็สร้าง dashboard ไม่ได้จริงมั้ย
ดังนั้น เราต้อง connect data เข้ามาใน Looker Studio ของเราก่อน
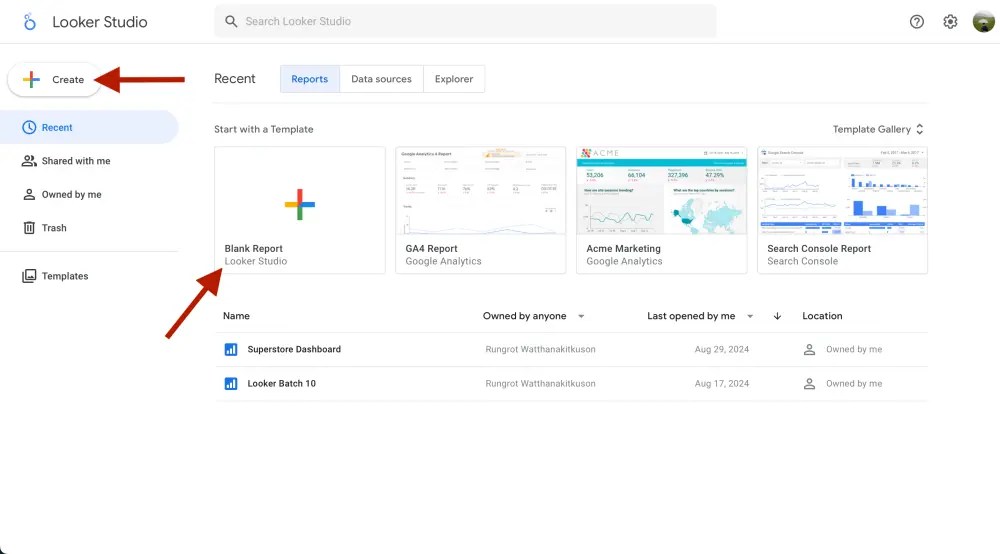
ขั้นตอนแรกให้เราไปที่เว็บไซต์ https://lookerstudio.google.com/

ให้เรากดไปที่ปุ่มรูป + Create หรือ + Blank Report เพื่อสร้าง dashboard ใหม่
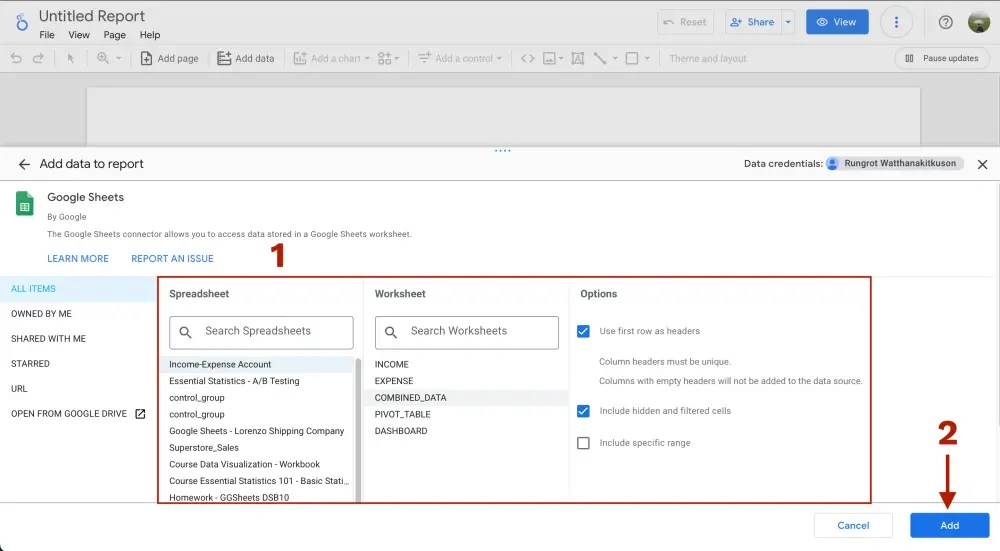
จากนั้นจะขึ้นหน้าต่างให้ Add data to report ซึ่งอย่างที่เราบอกมีให้ import data เยอะมาก แต่ครั้งนี้เราจะเลือกเป็น Google Sheets

จากนั้นเราเลือกชีทที่เราจะใช้ทำเป็น dashboard
- Spreadsheet = เลือกไฟล์ Google Sheets จากใน Google Drive
- Worksheet = เลือก worksheet จากไฟล์ที่เราจะสร้าง dashboard
- Options = เราจะเลือกว่าแถวแรกของ table เป็น headers และดึงแถวที่ถูกซ่อนและถูกกรองมาด้วย
ถ้าเลือกเสร็จแล้ว กด Add > ADD TO REPORT ได้เลย
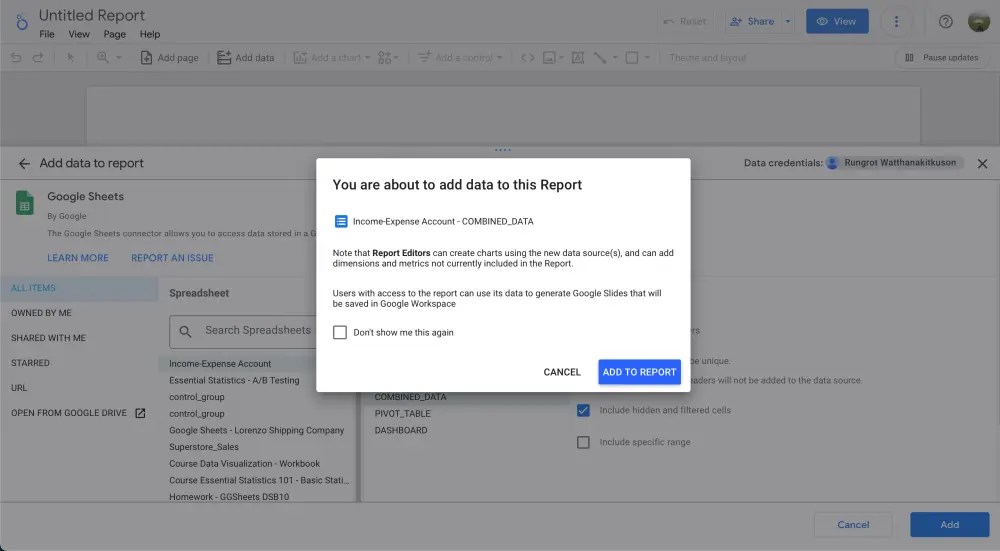
และเราจะได้หน้าต่างที่พร้อมสำหรับการทำ dashboard กันแล้ว หน้าตาคล้ายๆกับที่เราทำ pivot table เลย
ทุกคนสามารถเข้าไปอ่านคู่มือการใช้ Looker Studio เบื้องต้นได้ที่ https://support.google.com/looker-studio/answer/9171315?hl=en#zippy=%2Cinstructions
ก่อนจะเริ่มสร้าง chart จัดเรียง dashboard เราจะพาทุกคนไปรู้จักกับ Data freshness ฟีเจอร์ที่ทำให้งานของเราเริ่มมีความ automation มากขึ้น ทำให้ data ของเราถูกอัพเดทอัตโนมัติเมื่อมี data point ใหม่ๆเข้ามา เหมือนผักผลไม้ที่ถูกแช่ในตู้เย็น สดใหม่ตลอด

ขั้นตอนแรกให้ไปที่แถบเมนูเลือก Resource > Manage added data sources
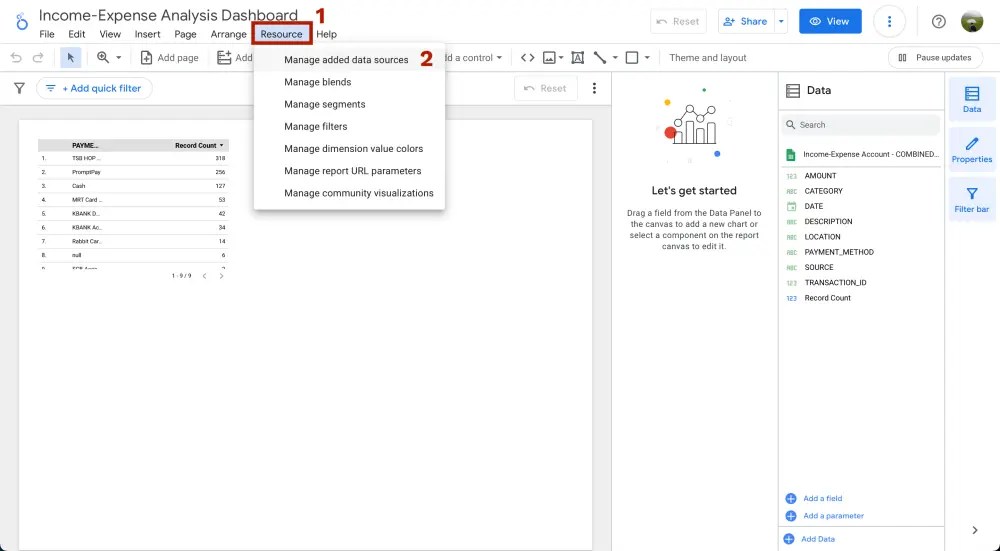
จากนั้นจะขึ้นหน้าต่าง data ทั้งหมดที่เราเพิ่มเข้าไปใน dashboard ในที่นี้มีอยู่ไฟล์เดียวให้ไปส่วนของ Action คลิกคำว่า EDIT

จะขึ้นหน้าต่างข้อมูลทั้งหมดของไฟล์ data ทุกคอลัมน์, data type แต่ละอันคอลัมน์ เราสามารถเช็คและตั้งค่าตรงนี้ได้
แต่ให้เราสังเกตขวาบนของจอจะเห็นคำว่า Data freshness ให้เราคลิกเข้าไป
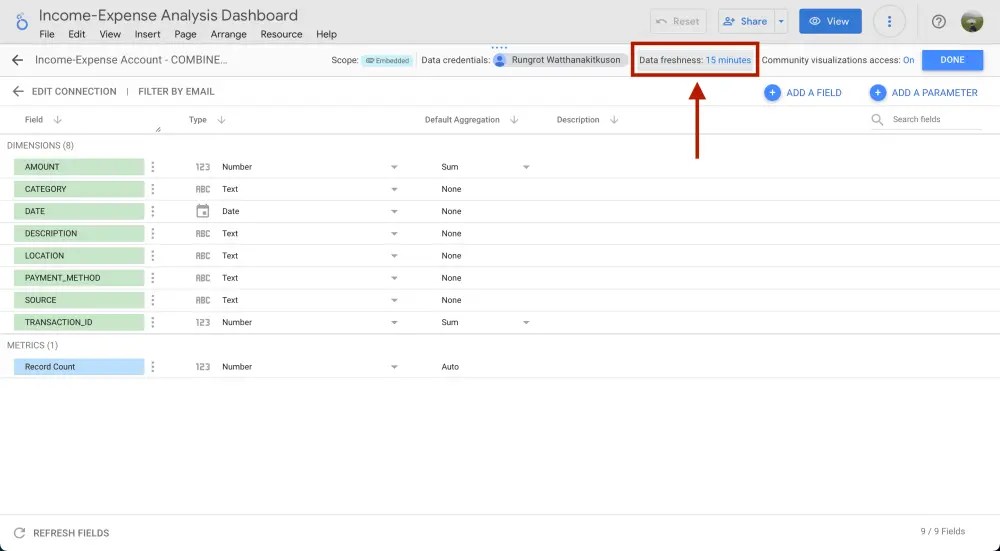
แล้วเลือกได้เลยว่าอยากจะให้ data ใน dashboard อัพเดททุกๆกี่นาทีกี่ชั่วโมง โดย default จะเป็นทุกๆ 15 นาที
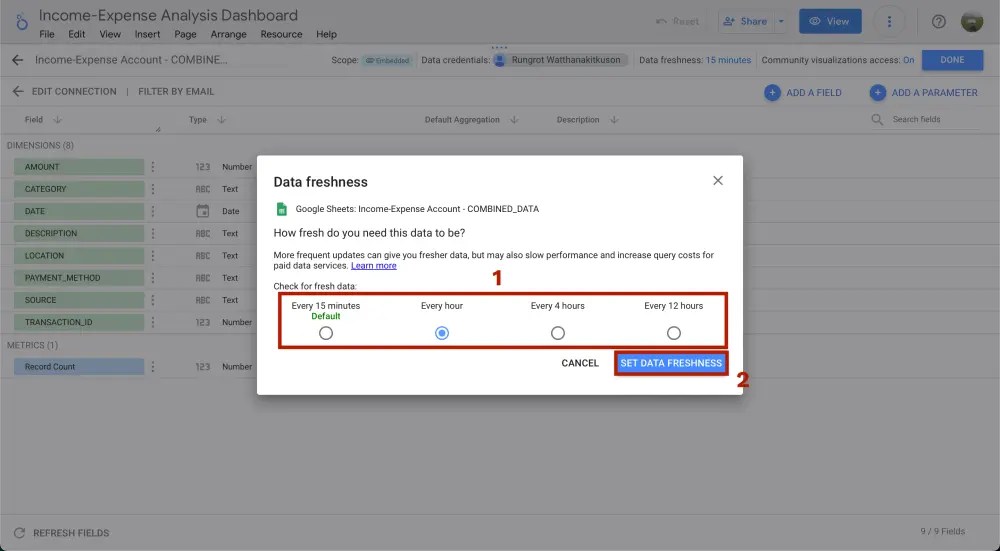
Data freshness
สังเกตว่า ถ้าข้อมูลเรายิ่งเยอะและเราให้ data อัพเดทบ่อยๆเท่าไหร่ dashboard เราจะยิ่งช้าไปด้วยนะ นี่จึงเป็นเรื่องที่ต้อง trade off กันนิดนึง
Create (Chart)
เราขอแนะนำ tools สำหรับการสร้าง chart เรียงตามลำดับการใช้งาน แบ่งเป็น 5 โซน
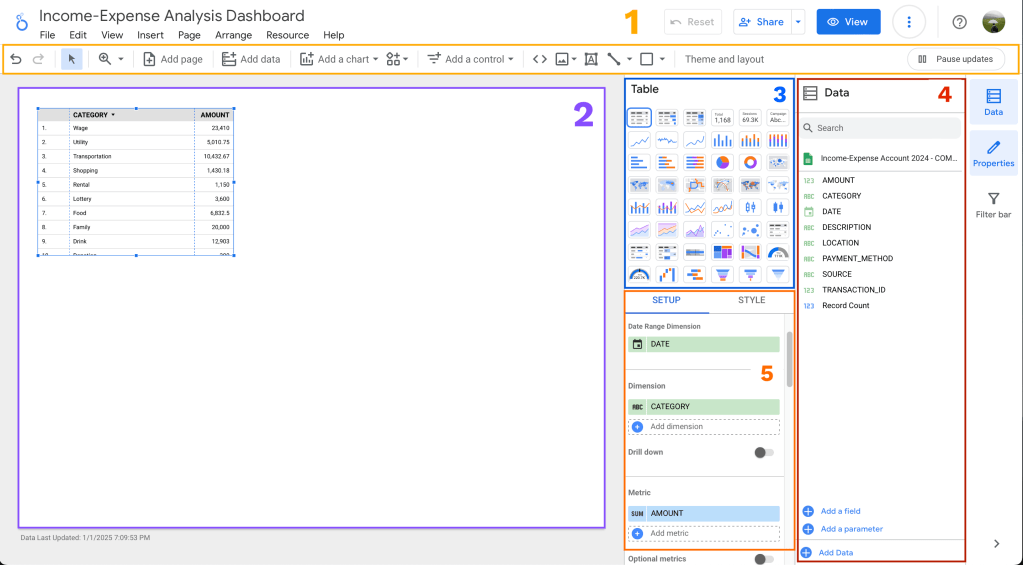
- โซนสีเหลือง เป็นส่วนของเครื่องมือที่คล้ายๆ Powerpoint เลย สามารถเพิ่มหน้า, chart, filter, เส้น/รูปร่าง ใส่ข้อความ เปลี่ยน theme
- โซนสีม่วง เป็น workspace ที่เราไว้ใช้ dashboard
- โซนสีน้ำเงิน เป็นโซนที่เราไว้เลือก chart ที่เราจะใช้
- โซนสีแดง เป็นส่วนที่โชว์ว่า dataset ของเรามี features อะไรอยู่บ้าง รวมถึงเราสามารถสร้าง calculated field เองได้
- โซนสีส้ม เป็นโซนที่เราลาก features จากโซนสีแดงมาใส่ที่ Dimension กับ Metric เพื่อสร้าง chart เหมือนกับการสร้าง pivot table ใน Google Sheets เลย และมีไว้ปรับแต่ง chart ของเรา
สังเกตว่า การสร้าง dashboard ใน Looker Studio จะลดขั้นตอนในการสร้าง pivot table ก่อนที่จะสร้าง chart เลย แต่ถ้าอยากเปลี่ยน chart เป็น table ก็เลือกได้จากโซนสีน้ำเงิน
Share (Dashboard)
เราขอแชร์ตัวอย่าง dashboard ที่เราทำมากับข้อมูลชุดนี้มาให้ดูนะคร้าบ เผื่อทุกคนจะได้มีแนวทางไปปรับใช้เป็นของตัวเอง
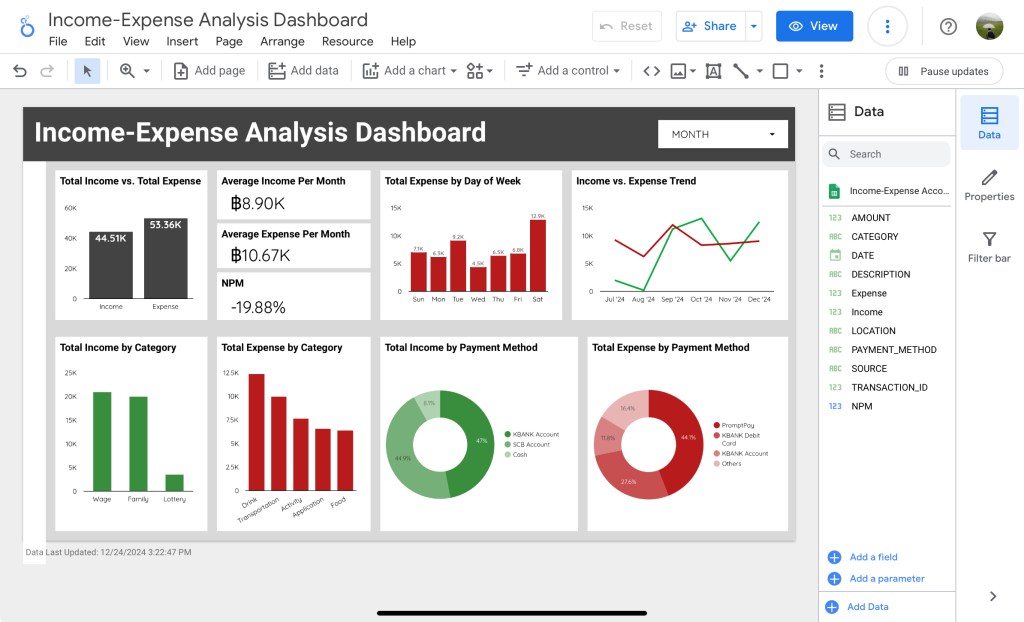
ตัวอย่าง Income-Expense Analysis Dashboard จาก Looker Studio
Epilogue
สุดท้ายเรามีสมการหนึ่งที่ทุกคนสามารถเข้าใจได้

สิ่งที่เราได้จากสมการข้างบนนี้เรียบง่ายมากๆ จริงมั้ย
- หาเงินให้ได้เยอะๆ และควบคุมค่าใช้จ่ายให้น้อยที่สุด สิ่งที่ไม่จำเป็นในชีวิตมากก็ไม่ควรซื้อแล้วเงินเก็บจะเยอะแน่นอน
- แต่ถ้าหาเงินได้เยอะ แต่ก็ใช้เยอะ อยากซื้อทุกอย่างที่อยากจะได้โดยไม่วางแผนเลย สุดท้ายเงินเก็บก็เหลือน้อยอยู่ดี
แต่ชีวิตจริงปฏิบัติย๊ากยากกกกกจังค้าบบบบบ น้ำตาไหลนิดนึงเลย
แต่วันก่อนเราได้ฟัง podcast คุณภาพจากช่อง THE STANDARD WEALTH อย่าง NEW GEN INVESTOR EP.25 ตั้งแต่นาทีที่ 1:35 ถึง 6:57

นับ 1-5 เรื่องการเงินที่ ‘มนุษย์เงินเดือน’ ต้องรู้ก่อนอายุ 30 | NEW GEN INVESTOR EP.25
ทำให้เราเปลี่ยนแนวคิดจากสมการข้างบนให้เป็นสมการนี้เลย

เมื่อเราได้รับเงินเดือนหรือค่าจ้างมาให้วันแรก อยากให้ทุกคนออมก่อนใช้ ไม่ใช่ใช้ก่อนออม เพราะไม่มีอยู่จริง 555555
อาจจะเริ่มซัก 5% หรือ 10% จากเงินที่เราได้มาเพื่อออมและลงทุนในระยะยาวก่อนเก็บไว้ใช้ รับรองว่ามีเงินเก็บอย่างแน่นอน
ดังนั้น dashboard ที่ได้ลงมือทำเป็นเพียงมอนิเตอร์ที่ track ให้เรารู้ว่าค่าใช้จ่ายในส่วนไหนน้อยหรือมาก เห็นแนวโน้มที่อาจจะเกิดขึ้นได้ สำคัญคือเราต้องปรับการใช้ชีวิตให้ค่าใช้จ่ายน้อยที่สุด และหาช่องทางที่เราจะสามารถหาเงินได้มากขึ้น
Comments

















































































Leave a comment