
ชีวิตของทุกคนไม่ว่าจะช่วงวัยไหน วัยเรียนหรือวัยทำงาน ต่างคนต่างก็อยากจะหาเวลาพักผ่อนให้ตัวเองจากการเรียนและทำงานอันแสนเหนื่อยล้า นึกภาพถึงวันที่ได้ออกตามของอร่อย ถ่ายรูปเช็คอินในสถานที่สวยๆกันใช่มั้ย เราก็เป็น 555555

แต่ก็เกิดปัญหาขึ้นอีกว่าไม่รู้จะไปไหนดี ข้อมูลก็เยอะเกินไป ไม่ว่าจะเป็นที่พัก ร้านอาหาร สถานที่ท่องเที่ยวเยอะจนเลือกไม่ถูก ที่สำคัญสุดเลยคือ แต่ละคนมีงบกับเวลาที่จำกัดอีก

ในบทความนี้เราเลยจะลองสวมบทเป็นมนุษย์คนหนึ่งอาศัยอยู่ใน New York City ที่อยากจะวางแผนไปเที่ยวในปีหน้า (2024) แต่ด้วยงบและเวลาที่จำกัด ทำให้เขาคนนี้ไปเที่ยวได้แค่ภายในประเทศเท่านั้น ร้องไห้แล้ว 5555555
เราจะใช้ข้อมูลจาก nycflights23 และ skills เกี่ยวกับ R Programming การทำ data transformation เพื่อวิเคราะห์ข้อมูลชุดนี้เพื่อช่วยให้พนักงานคนนี้แก้ปัญหาและตัดสินใจสถานการณ์ที่เกิดขึ้นนี้ได้ดียิ่งขึ้น

สาเหตุที่เราเลือกใช้ภาษา R เพราะ
- เป็นภาษาที่ง่ายมากสำหรับผู้ที่เริ่มต้นทำงานเกี่ยวกับ data มีฟังก์ชันทางสถิติมากมาย แบบไม่ต้อง def function ขึ้นมาเอง บอกเลยว่านอนไปพิมพ์ไปได้เลย เด๋วววววววววว!!
- เขียน code เสร็จอ่านแล้วเข้าใจเลยว่า process งานแต่ละขั้นกำลังทำอะไรอยู่
- ข้อดีของการเขียน code เลยคือ รองรับ data ได้จำนวนมาก รันเร็ว ไม่ยุ่งยากเท่ากับการผูกสูตรใน Google Sheets หรือ Microsoft Excel เลย
- สามารถเริ่มต้นเขียน code ง่ายๆผ่านเว็บ browser ได้เลย และฟรี! เช่น Google Colab
- ติดตั้งและโหลด libraries ที่ต้องการใช้
- ทำความเข้าใจกับข้อมูล
- เตรียมข้อมูลก่อนเริ่มวิเคราะห์เสมอ
- Let’s start to Analyze data!
- สนามบินที่มีประสิทธิภาพมากที่สุดในแง่ความตรงต่อเวลา
- LaGuardia Airport มีความตรงต่อเวลามากน้อยแค่ไหน
- แล้วเราควรเลือกสายการบินไหนดีนะ?
- เราควรเดินทางจาก LGA ช่วงเดือนไหนดีถึงดีที่สุด
- สายการบินไหนที่ใช้เวลาเดินทางน้อยที่สุด
- สายการบินไหนที่มีระยะทางไกลมากที่สุด
- จุดหมายใดที่เป็นที่นิยมมากที่สุด 5 อันดับแรกในปี 2023
- แผนการเดินทางในปี 2024
- More posts
ติดตั้งและโหลด libraries ที่ต้องการใช้
อันดับแรก เราต้องเลือกเครื่องมือให้เหมาะสมกับงานที่เราทำกันก่อน ซึ่งเครื่องมือที่เราใช้กันใน programming เราเรียกว่า library หรือ package นั่นเอง

โดย library ที่เราเลือกใช้ในครั้งนี้มีทั้งหมด 4 packages ดังนี้
- glue เป็นเหมือนกาวที่คอยเชื่อมระหว่าง text กับตัวแปรเวลาที่เรา print ข้อความบางอย่างออกมา
- conflicted ไว้สำหรับช่วยแก้การเรียกใช้ฟังก์ชันหรือตัวแปรที่ซ้ำกันโดยการเรียกใช้ต้องระบุชื่อ package ของฟังก์ชันหรือตัวแปรนั้นๆด้วย
- tidyverse เป็น package ที่ทรงพลังมากในการทำ data transformation หรือแม้กระทั่งการทำ data visualization เช่น dplyr, stringr, ggplot2 เป็นต้น
- nycflights23 เป็นการเรียก dataset ที่เกี่ยวกับ flights, planes, airports, weather, airlines ของ New York City ปี 2023 ทั้งหมด
# Install packages
install.packages(c("glue", "conflicted", "tidyverse", "nycflights23"))# Load packages
library(glue)
library(conflicted)
library(tidyverse)
library(nycflights23)ทำความเข้าใจกับข้อมูล
และตอนนี้เราก็มีเครื่องมือที่ดีติดตัวแล้ว ต่อมาก็เป็นเรื่องของ material ที่เราจะ create ชิ้นงานออกมา นั่นก็คือ DATA นี่เอง ถ้าเราไม่ทำความรู้จักกับ material ดีพอ ก็อาจจะรีดประสิทธิภาพได้ไม่สุดเท่าไหร่
ไม่ว่าจะเป็นงาน data analysis หรือ data science ก็ต้องศึกษาข้อมูล (exploration) ให้ดีซะกัน ซึ่ง material ที่เราจะใช้มีอยู่ 3 ตัว นั่นคือ ข้อมูลเที่ยวบิน (flights), ข้อมูลสนามบิน (airports), ข้อมูลสายการบิน (airlines)
โดยเราจะใช้ฟังก์ชัน summary() เพื่อเป็นการสรุปข้อมูลแต่ละ dataset ว่าแต่ละคอลัมน์มีหน้าตาประมาณไหนกันก่อน

ER Diagram แสดง relationship ของ NYCflights23 dataset
Flights dataset

Flights dataset ให้ข้อมูลต่างๆเกี่ยวกับไฟล์ทที่ถูกบินไปแล้วในช่วงปี 2023 จาก NYC ซึ่งเราจะใช้สำหรับการวิเคราะห์ว่าเราควรจะเดินทางไปไหนดี ขึ้นที่สนามบินไหน ลงที่ไหน ใช้สายการบินไหนดี โดยอิงจากข้อมูลปี 2023
summary(flights)
- year: ปีที่ไฟล์ทออกบิน
- month: เดือนที่ไฟล์ทออกบิน
- day: วันที่ไฟล์ทออกบิน
- dep_delay: เวลาที่ล่าช้าหรือเร็วกว่ากำหนดเมื่อเครื่องออกจากสนามบินต้นทาง มีหน่วยเป็น นาที
- arr_delay: เวลาที่ล่าช้าหรือเร็วกว่ากำหนดเมื่อถึงสนามบินปลายทาง มีหน่วยเป็น นาที
- carrier: ตัวอักษรย่อ 2 ตัวของสายการบินในไฟล์ทนั้นๆ
- origin: สนามบินต้นทางที่เครื่องออก
- dest: สนามบินปลายทางที่เครื่อง landing
- air_time: เวลาที่ใช้ในการบิน มีหน่วยเป็น นาที
- distance: ระยะทางระหว่างสนามบินต้นทางและปลายทาง มีหน่วยเป็น ไมล์ (mile)
Airports dataset

Airports dataset ให้ข้อมูลต่างๆเกี่ยวกับสนามบินทั้งหมดในทุกเที่ยวบิน เราจะใช้สำหรับการดูรหัสและชื่อของสนามบินที่เราจะเดินทางไป
summary(airports)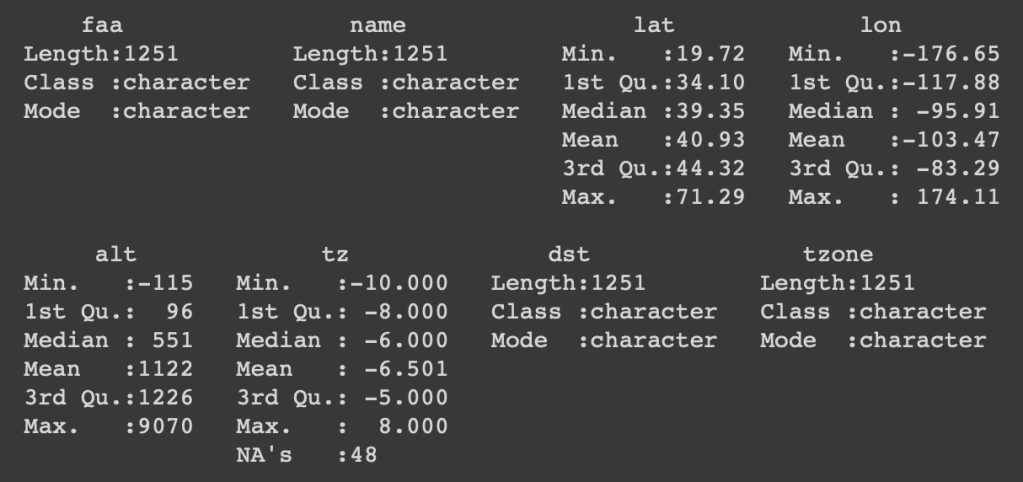
- faa: FAA airport code
- name: ชื่อสนามบิน
Airlines dataset

Airlines dataset ให้ข้อมูลต่างๆเกี่ยวกับชื่อสายการบินกับรหัสผู้ให้บริการ เราจะใช้สำหรับการดูรหัสและชื่อสายการบินที่เราจะใช้บริการ
summary(airlines)
- carrier: อักษรย่อ 2 ตัวของสายการบิน
- name: ชื่อเต็มของสายการบิน
ข้อมูลจาก: https://cran.r-project.org/web/packages/nycflights13/nycflights13.pdf
เตรียมข้อมูลก่อนเริ่มวิเคราะห์เสมอ
ทุกครั้งที่มีการวิเคราะห์ข้อมูล เราควรที่จะตรวจสอบก่อนว่าข้อมูลของเรานั้นสมบูรณ์หรือไม่ นั่นคือ กระบวนการเตรียมข้อมูล (preparation) ซึ่งเวลาส่วนใหญ่ในงานของ data analyst / data scientist มักจะอยู่ที่ตรงนี้กันเป็นหลักเลย
ไม่ว่าจะเป็นการเช็ค data types, มีข้อมูลบาง records ที่ซ้ำกัน หรือ missing values หรือไม่, แม้กระทั่งข้อมูลอยู่ใน format ที่ควรจะเป็น, ข้อมูลมี outliers หรือไม่ เป็นต้น จริงๆมีอีกเยอะมากกกกกกก ร้องไห้แล้ว 55555555555
โดยอันดับแรกเราจะขอเช็ค data types ของข้อมูลก่อนโดยใช้ฟังก์ชัน glimpse() จาก library tidyverse
glimpse(flights)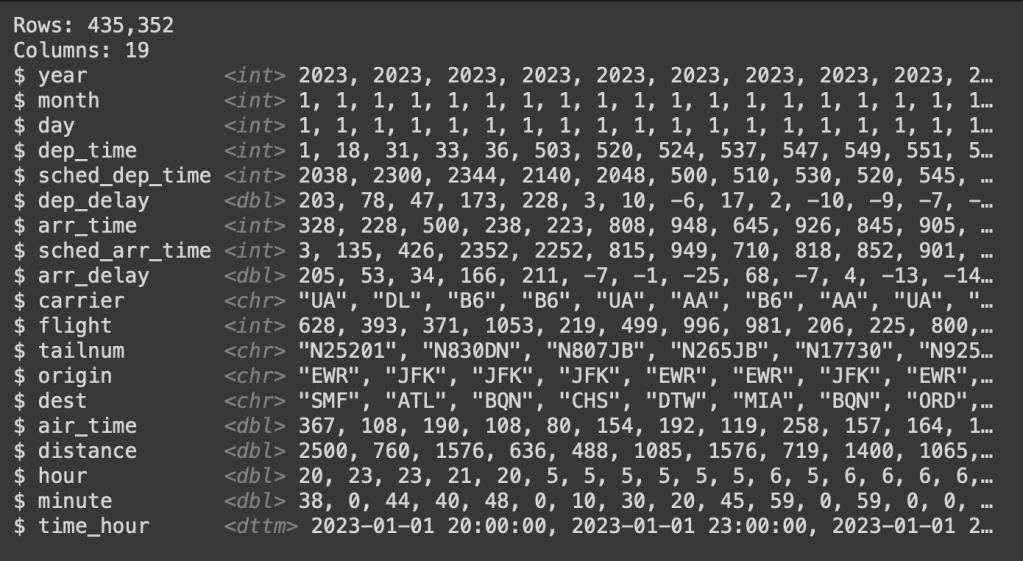
glimpse(airports)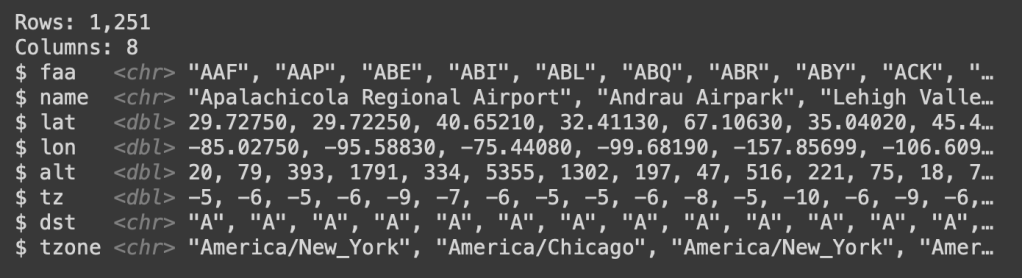
glimpse(airlines)
สังเกตว่า คอลัมน์ hour และ minute ควรจะมี data types เป็น integer ไม่ใช่ numeric
โดยฟังก์ชันที่ใช้ใน convert data types เป็น integer คือ as.integer()
Note: แต่เนื่องจากในบทความนี้เราไม่มีความจำเป็นที่จะต้องใช้สองคอลัมน์นี้ เราจึงขอละขั้นตอนนี้ไว้ในฐานที่เข้าใจนะคร้าบบบ
ค้นหา records ที่ซ้ำกันในทุก dataset
ใน dataset เราอาจพบ data point บาง record ที่ซ้ำกัน ซึ่งอาจจะเกิดจากความผิดพลาดจาก human error หรือการจัดเก็บข้อมูล
ดังนั้น เราจึงใช้ฟังก์ชัน duplicated() สำหรับการหาข้อมูลบาง records ที่ซ้ำกัน (full duplicates) หามีข้อมูลที่ซ้ำกัน ฟังก์ชันนี้จะ return ค่าเป็น TRUE โดยเราจะใช้คู่กับฟังก์ชัน sum() เพื่อหาผลรวมว่า dataset ดังกล่าวมีจำนวน full duplicates ทั้งหมดกี่ records
ก่อนที่จะไปดูการค้นหา full duplicates กัน เราขอแนะนำ 2 ฟังก์ชันให้ทุกคนรู้จักกันก่อน นั่นคือ
1. print() เป็นฟังก์ชันสำหรับปริ้นข้อความที่เราต้องการไปโชว์ในหน้าต่าง console
2. glue() เป็นฟังก์ชันจาก library glue ใช้สำหรับเชื่อมข้อความกับตัวแปรเข้าด้วยกัน
# Finding full duplicates for each datasets
print(glue("Flights dataset have {sum(duplicated(flights))} full duplicates."))
print(glue("Airports dataset have {sum(duplicated(airports))} full duplicates."))
print(glue("Airlines dataset have {sum(duplicated(airlines))} full duplicates."))
จากผลการค้นหาข้างต้นพบว่า ไม่มี full duplicates สำหรับทุก dataset เลย เราจึงเข้าสู่ขั้นตอนต่อไป
นับจำนวน missing values ที่มี
เราจะใช้อยู่ด้วยกัน 3 ฟังก์ชันหลักๆในการนับจำนวน missing values ออกมาเป็นรูปแบบของ % กัน ได้แก่
- complete.cases() ฟังก์ชันนี้หากพบเจอว่าแถวใดคอลัมน์ใดมี missing values อยู่ จะ return ค่าเป็น FALSE
- mean() มีส่วนนี้จะมีหน้าที่คำนวณว่าจากค่า TRUE (1) กับ FALSE (0) ทั้งหมดที่ return จากฟังก์ชัน complete.cases() โดยเฉลี่ยแล้วพบค่า TRUE เป็นร้อยละเท่าไหร่ ซึ่งจะมีค่าอยู่ระหว่าง 0 ถึง 1 เท่านั้น
- round() เป็นฟังก์ชันที่จะทำให้ตัวเลขนั้นๆมีจำนวนทศนิยมตามที่เราต้องการ
# Counting missing values
print(glue("Flights dataset have {round((1 - mean(complete.cases(flights)))*100,2)} % missing values."))
print(glue("Airports dataset have {round((1 - mean(complete.cases(airports)))*100,2)} % missing values."))
print(glue("Airlines dataset have {round((1 - mean(complete.cases(airlines)))*100,2)} % missing values."))
ซึ่งผลที่ได้ข้างต้นพบว่ามีเพียง Airlines dataset เท่านั้นที่ไม่มี missing values เลย
ดังนั้น ในบทความนี้เราจะใช้วิธีการ drop missing values ซึ่งฟังก์ชันที่ใช้ก็ตรงตัวมาก นั่นคือ drop_na() หรือจะใช้ na.omit() ก็ได้เหมือนกันนะคร้าบ
พอมาถึงตรงนี้แล้ว เราขออธิบายการทำ data transformation ซักเล็กน้อยก่อนนะ
Data Transformation เป็นเหมือนการเอา data มาแปลงร่างตามที่เราต้องการเหมือน transformer เลย 555555

ซึ่ง library ที่ใช้สำหรับการ transform data นั่นคือ dplyr ใน library tidyverse นี่เอง!! หลักๆแล้ว core function ที่ทุกคนควรทำความรู้จักก่อน 5 ฟังก์ชัน คือ
- select() : เลือกคอลัมน์ใน dataframe ที่เราต้องการ
- filter() : กรองข้อมูลตามเงื่อนไขที่เรากำหนด
- mutate() : สร้างคอลัมน์ใหม่
- group_by() : จัดกลุ่มข้อมูลตามคอลัมน์ ซึ่งมักจะใช้คู่กับฟังก์ชันที่ 5 ของเรา
- summarise() หรือ summarize() : สรุปผลข้อมูลโดยใช้ aggregate function เช่น n(), sum(), min(), max(), mean(), median(), std() เป็นต้น
แถมซักอีก 1 ฟังก์ชันซึ่งเราจะแอบๆใช้ในบทความนี้ด้วยหลังจากนี้ นั่นคือ rename() สำหรับการเปลี่ยนชื่อคอลัมน์ใน dataframe
อีกหนึ่งสิ่งที่ขาดไปไม่ได้เลย นั่นคือ pipe operator ใช้สัญลักษณ์เป็น %>% เหมือนกับการต่อท่อเชื่อมการทำงานของแต่ละฟังก์ชัน สำหรับ base R จะใช้สัญลักษณ์เป็น |>
# Clean missing values by dropping NA
clean_flights <- tibble(flights %>%
drop_na())
clean_airports <- tibble(airports %>%
drop_na())และเพื่อให้ชื่อตัวแปรเป็นไปในทิศทางเดียวกัน เราจึงขอเปลี่ยนชื่อ dataset ของ airlines ที่ไม่มี missing values
clean_airlines <- tibble(airlines)Note: tibble() เป็นฟังก์ชันที่ใช้ในการแปลง object ที่เป็น data.frame เป็น tibble ซึ่งต่างจาก data.frame ตรงที่เวลาแสดงผลลัพธ์ใน console จะดูสวย เป็นระเบียบ อ่านง่ายมากขึ้น
Let’s start to Analyze data!
สนามบินที่มีประสิทธิภาพมากที่สุดในแง่ความตรงต่อเวลา
เวลาเป็นสิ่งที่มีค่ามาก แค่การไปสนามบินแล้วยังต้องนั่งรอเวลาขึ้นเครื่อง แล้วต้องเจอกับคำว่า delayed หรือ canceled ก็ทำให้ใจเจ็บได้ สิ่งที่เราอยากเห็นคือคำว่า boarding ที่ตรงเวลาหรือเร็วกว่ากำหนดเท่านั้น

อย่างนั้นจะดีกว่ามั้ยถ้าเราสามารถวิเคราะห์ได้ว่าสนามบินไหนที่มีระบบการจัดการเรื่องเวลาได้ดีเป็นอันดับต้นๆ เพื่อรักษาเวลาที่เป็นของมีค่าของเรา
ot_dep_rate <- clean_flights %>%
mutate(dep_type = ifelse(dep_delay <= 5, "On Time", "Delayed")) %>%
group_by(origin) %>%
summarise(ot_dep_rate = sum(dep_type == "On Time") / n()) %>%
arrange(desc(ot_dep_rate))
ot_dep_rate
Note: ot ย่อมาจาก On Time
จากการสังเกตพบว่า LaGuardia Airport (LGA) มีอัตราที่เครื่องบินจะบินได้ตรงกำหนดสูงที่สุดเมื่อเทียบกับ John F. Kennedy International Airport ( JFK) และ Newark Liberty International Airport (EWR)
LaGuardia Airport มีความตรงต่อเวลามากน้อยแค่ไหน
เราจะ filter เฉพาะ flights ที่บินออกจาก LGA เท่านั้น และใช้ histogram chart เพื่อแสดงการกระจายตัวของ departure time delayed
lga_flights <- clean_flights %>%
dplyr::filter(origin == "LGA")## Preview flights from LGA airport
lga_flights %>%
select(carrier, flight, tailnum, origin, dest) %>%
head()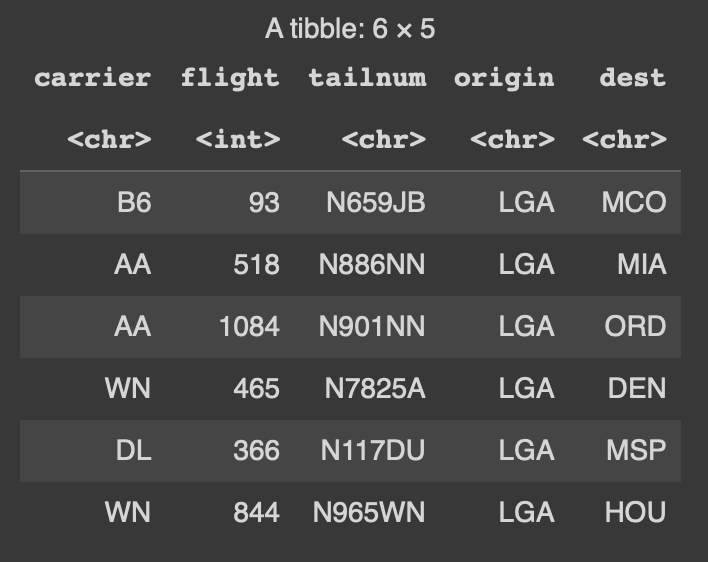
dtb_delayed_lga <- lga_flights %>%
dplyr::filter(dep_delay > 0) %>%
select(dep_delay) %>%
ggplot(aes(x = dep_delay)) +
geom_histogram(bins = 30,
fill = "lightblue",
color = "black") +
coord_cartesian(xlim = c(0,900),
ylim = c(0,30000)) +
theme_minimal() +
labs(title = "Distribution of departure time delayed of LGA",
x = "Departure Time Delayed",
y = "Number of Flights",
caption = "Source: New York City Flights 2023 from nycflights23 package")Note: dtb ย่อมาจาก Distribution
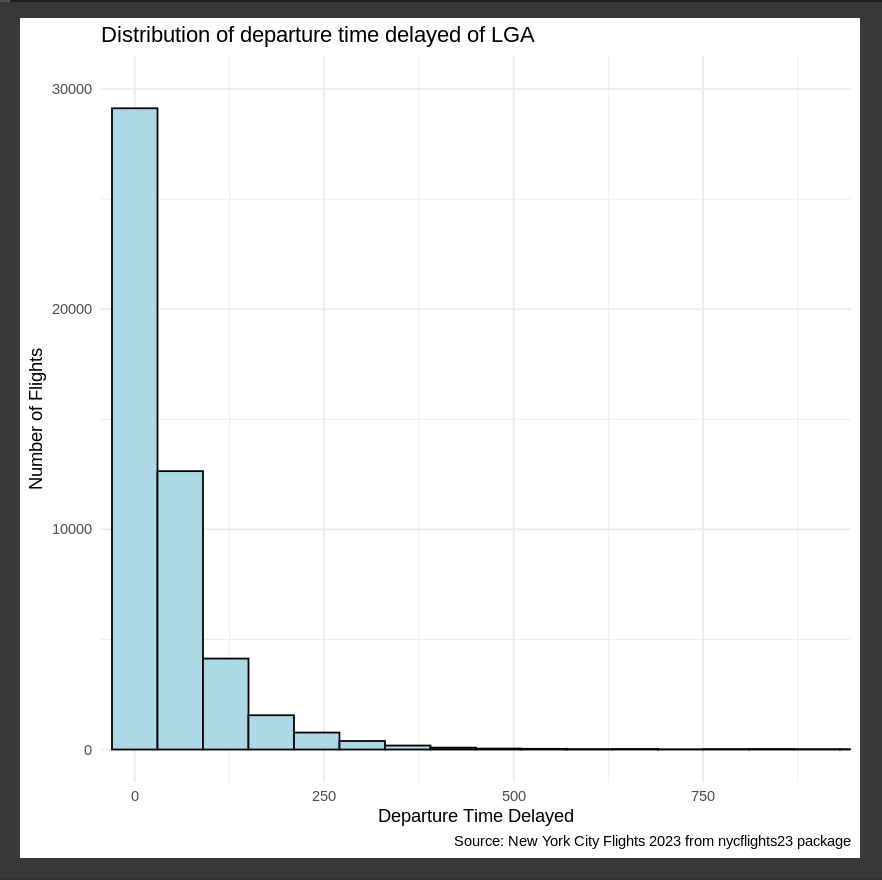
## Summarise statistical data for this histogram
lga_flights %>%
dplyr::filter(dep_delay > 0) %>%
select(dep_delay) %>%
summarise(min_delay = min(dep_delay),
mean_delay = mean(dep_delay),
median_delay = median(dep_delay),
sd_delay = sd(dep_delay),
max_delay = max(dep_delay)
)
แล้วเราควรเลือกสายการบินไหนดีนะ?
หลายครั้งที่เวลาเราจะไปเที่ยวแล้วเลือกการเดินทางโดยใช้เครื่องบิน สายการบินก็มีผลต่อการตัดสินใจของเราเช่นกัน ตัวอย่างเช่น ถ้าเป็นของไทย สายการบินที่เรามักเลือกเป็นอันดับต้นๆ แล้วราคาเป็นมิตรสุดๆ และขึ้นชื่อเป็นสายการบินราคาประหยัดที่ตรงเวลาที่สุด ก็จะเป็น Thai AirAsia เป็นต้น (เค้าไม่เคยสปอนเซอร์เลย แต่ใช้บริการประจำ 55555)

recommend_airlines_list <- lga_flights %>%
group_by(carrier) %>%
summarise(mean_dep_delay = mean(dep_delay),
median_dep_delay = median(dep_delay),
sd_dep_delay = sd(dep_delay)) %>%
arrange(mean_dep_delay)
recommend_airlines_list
จากการวิเคราะห์พบว่าสายการบิน Republic Airlines (YX) มีค่าเฉลี่ยของเวลาเครื่องออกต่ำที่สุด รองลงมาคือ สายการบิน Endeavor Air (9E) และสายการบิน United Air Lines (UA)
เราควรเดินทางจาก LGA ช่วงเดือนไหนดีถึงดีที่สุด
ช่วงเวลาก็เป็นอีกสิ่งที่สำคัญต่อการเดินทาง ว่าเราควรจะไปเที่ยวในช่วงไหนดี โดยในกรณีนี้เราจะขอ based on เวลาเครื่องออก
สมมติว่า เราจะใช้วันลาพักร้อนที่บริษัทมีให้โดยไม่คำนึงถึงวันหยุดปกติ

flyout_lga <- lga_flights %>%
group_by(month) %>%
summarise(mean_dep_delay = mean(dep_delay),
median_dep_delay = median(dep_delay),
sd_dep_delay = sd(dep_delay),
frequency = n()) %>%
arrange(desc(mean_dep_delay))
flyout_lga
lga_flights %>%
ggplot(aes(x = factor(month), y = dep_delay)) +
geom_boxplot(outlier.color = "darkred",
outlier.alpha = 0.3) +
theme_minimal() +
labs(title = "Distribution of departure time delayed of LGA by Months",
x = "Months",
y = "Departure Time Delayed",
caption = "Source: New York City Flights 2023 from nycflights23 package")
จากตารางสรุปและ chart พบว่า flights ทั้งหมดจาก LaGuardia Airport ในเดือนพฤศจิกายนของปี 2023 ใช้เวลาเครื่องออกจากสนามบินน้อยที่สุดเมื่อเทียบกับทุกเดือน รองลงมา คือ เดือนตุลาคม 2023 และ เดือนพฤษภาคม 2023
สายการบินไหนที่ใช้เวลาเดินทางน้อยที่สุด
การไปถึงจุดหมายได้เร็วที่สุดก็ทำให้เรามีเวลาพักผ่อนเมื่อถึงจุดหมายได้มากขึ้นเท่านั้น เพราะเวลาคือสิ่งที่มีค่ามากที่สุด

ฉะนั้นแล้ว เราก็ขอมารื้อฟื้นความรู้วิชาคณิตศาสตร์และวิทยาศาสตร์กันซักเล็กน้อย หลายคนน่าจะคุ้นๆกับสมการนี้กัน v = d/t
เมื่อ v คือ อัตราเร็ว (velocity) หรือ ความเร็ว (speed)
d คือ ระยะทาง (distance) หรือ การกระจัด (displacement)
และ t คือ เวลา (time)
สิ่งที่เราสามารถเห็นได้ชัดจากสมการเลยคือ
1. หากเราต้องการรู้อัตราเร็ว/ความเร็ว จำเป็นต้องหา ระยะทาง/การกระจัด และ เวลา ซะก่อน
2. อัตราเร็ว/ความเร็ว จะสูง ถ้า เราใช้เวลาในการเดินทางน้อยกับระยะทางที่ไกลๆ
ขั้นแรก เราจะทำการแปลงเวลาที่ใช้ในการเดินทาง (air_time_hour) จากนาทีเป็นชั่วโมงกันก่อน ซึ่งใช้ความรู้ที่ง่ายมากๆว่า 1 ชั่วโมง เท่ากับ 60 นาที
lga_flights$air_time_hour = round(lga_flights$air_time / 60, 1)ขั้นต่อไป เรามาคำนวณ speed จากสมการเมื่อสักครู่นี้กัน!!
avg_lga_flights <- lga_flights %>%
mutate(avg_speed = distance / air_time_hour) %>%
arrange(desc(avg_speed)) %>%
select(carrier, tailnum, avg_speed, distance)
avg_lga_flights %>%
head()
จากการวิเคราะห์พบว่า สายการบินที่มีโอกาสจะใช้เวลาในการเดินทางน้อยที่สุด คือ Southwest Airlines (WN) รองลงมาคือ Delta Airlines (DL) และ American Airlines (AA)
สายการบินไหนที่มีระยะทางไกลมากที่สุด
อีกหนึ่งปัจจัยที่จะทำให้เราตัดสินใจว่าไม่อยากเดินทางไปที่นี่เลย นั่นคือเรื่องของระยะทางที่มากเกินไป แค่เราเปิด Google Maps แล้วรู้สึกว่าอยู่ไกลจากที่เราต้องออกเดินทางมากเกินไปก็เป็นท้อแล้ว
แต่ถ้ามันเป็นสถานที่ที่เราอยากไปจริงๆก็อาจจะละทิ้งเรื่องนี้ไปโดยไม่มีเหตุผลเหมือนกัน โดยในบทความนี้จะไม่นับเหตุผลนี้มารวมอยู่ในการวิเคราะห์นะค้าบ

โดยเราจะวิเคราะห์จากสายการบินที่มี flights การบินเกินกว่า 1000 km เป็นต้นไป
lga_long_haul_flights <- lga_flights %>%
dplyr::filter(distance > 1000) %>%
group_by(carrier) %>%
summarise(n_flights = n(),
mean_distance = mean(distance)) %>%
arrange(desc(mean_distance))
lga_long_haul_flights
จากการวิเคราะห์พบว่า สายการบิน United Air Lines (UA) มีระยะทางการบินเฉลี่ยทุกไฟล์ทสูงที่สุด รองลงมา คือ สายการบิน Southwest Airlines (WN) และ Skywest Airlines (OO) ตามลำดับ
จุดหมายใดที่เป็นที่นิยมมากที่สุด 5 อันดับแรกในปี 2023
ทุกวันนี้เรามีแหล่งข้อมูลหรือ social media ต่างๆมากมายให้ได้หาข้อมูลต่างๆ ไม่ใช่แค่เรื่องการท่องเที่ยวและการเดินทางเท่านั้น อีกหนึ่งสิ่งที่ผลมากๆต่อคนรุ่นใหม่คือ influencer ที่หลายคน follow หรือติดตามผลงานกัน หลายคนมี inspire หลายอย่างที่บางทีก็จินตนาการอยากไปอยู่ในจุดๆเดียวกับคนๆนั้น

แต่อย่างไรก็ตามถ้าเรามีข้อมูลต่างๆที่บอกเราได้ว่าตอนนี้คนทั่วไปเค้าไปที่ไหนกัน (ดูจากสนามบินปลายทางที่ไป landing กัน; dest) ก็คงเอามาเป็นอีกทางเลือกในการตัดสินใจที่ดีเลย
pop_dest_2023 <- lga_flights %>%
count(dest) %>%
arrange(desc(n))
pop_dest_2023 %>%
head(5)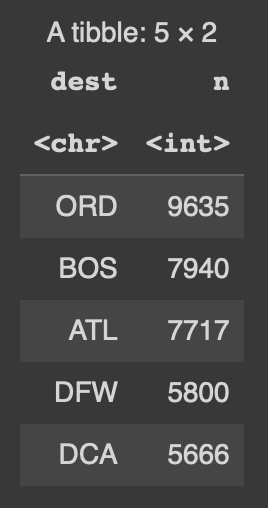
จากผลการวิเคราะห์พบว่า สนามบินที่คนส่วนใหญ่เลือกไปลงมากที่สุด คือ Chicago O’Hare International Airport (ORD)
รองลงมาคือ Boston Logan International Airport (BOS) และ Hartsfield-Jackson Atlanta International Airport (ATL)
แผนการเดินทางในปี 2024
จากข้อมูลต่างๆที่ได้วิเคราะห์มาแล้ว เราต้องเช็คก่อนว่าสนามบินปลายทางที่เราจะไปลงมีสายการบินรองรับจาก LaGuardia Airport หรือไม่
lga_flights %>%
dplyr::filter(dest %in% c("ORD", "BOS", "ATL") & month %in% c(10,11) & carrier %in% c("WN","DL","AA")) %>%
group_by(dest, carrier) %>%
summarise(num_of_flight = n()) %>%
inner_join(clean_airlines, by = "carrier") %>%
inner_join(clean_airports, by = c("dest" = "faa")) %>%
select(dest, name.y, carrier, name.x, num_of_flight) %>%
rename(dest_airport = name.y,
airline_name = name.x)สังเกตว่า code ด้านบนเราจะมีการแอบใช้ฟังก์ชัน inner_join() ด้วย ซึ่งเป็นฟังก์ชันสำหรับการนำ data จาก 2 table มาเชื่อมกันด้วย key บางอย่าง ซึ่งเราต้องดู relationship จาก ER diagram

ดังนั้น เราจึงมีแผนการเดินทางไปท่องเที่ยวออกเป็น 3 ตัวเลือก ดังนี้
1. ไปเที่ยว Chicago ด้วยการนั่งเครื่องบินจาก LaGuardia Airport ไปลง Chicago O’Hare International Airport (ORD) สามารถใช้บริการสายการบิน Delta Airlines (DL) และ American Airlines (AA)


2. ไปเที่ยว Boston ด้วยการนั่งเครื่องบินจาก LaGuardia Airport ไปลง Boston Logan International Airport (BOS) สามารถใช้บริการสายการบิน Delta Airlines (DL) และ American Airlines (AA)


3. ไปเที่ยวเมือง Atlanta ด้วยการนั่งเครื่องบินจาก LaGuardia Airport ไปยัง Hartsfield-Jackson Atlanta International Airport (ATL) ซึ่งสามารถใช้บริการสายการบิน Southwest Airlines (WN) และ Delta Airlines (DL)


โดยทั้ง 3 ตัวเลือกนี้ ช่วงที่ควรเหมาะกับการเที่ยวมากที่สุดคือช่วงเดือนตุลาคมถึงพฤศจิกายน ซึ่งเป็นช่วงฤดูใบไม้ร่วงกำลังจะเข้าช่วงฤดูหนาวพอดี

อ่านจบแล้ว คิดเห็นยังไงกันบ้างว่าการมี data + programming นั้นทรงพลังสุดๆไปเลย ถ้าชอบฝากกด like ใช่กด share ให้เพื่อนของทุกๆคนได้อ่านต่อกันด้วยนะคร้าบ : )
Comments

Leave a comment